SREチーム不在でも回せる!開発チーム主導で始める実用的なSLO/エラーバジェット運用
SLO/エラーバジェット運用とはどのようなものですか?
この記事の要点
Q: SLO(サービスレベル目標)とは何ですか?
Q: エラーバジェットとは何ですか?
Q: SREチームがいなくても運用できますか?
Q: 目標設定のポイントは?
現代のWebサービス開発において、「サービスの信頼性をどう保つか?」は重要な経営課題です。しかし、GoogleやAmazonのような専門のSRE(Site Reliability Engineering)チームを持つ企業ばかりではありません。
SLO(Service Level Objective) は、サービスの目標品質を数値で定義したもので、エラーバジェット は許容される失敗の量を示す概念です。例えば「99.9%の稼働率」というSLOを設定した場合、月間で43.2分のダウンタイムが許容されます。
これらの概念は、SREチームがいなくても開発チームだけで運用可能な実践的な手法として、近年スタートアップや中小企業でも注目されています。
SLO導入によって得られるメリットとは?
| 項目 | 内容 |
|---|---|
| SLOの役割 | サービス品質の目標を定量化し、チーム全体で共有可能な指標とする |
| エラーバジェット | 許容される失敗の量を可視化し、リリース判断や優先度決定に活用 |
| 開発チーム主導のメリット | 専門SREチームなしでも、自動化ツールで運用可能 |
| 導入のポイント | まずは少数のSLIから始め、段階的に拡充していく |
| 推奨ツール | Prometheus, Grafana, Datadog, New Relic |
なぜ開発チームでSLO運用が必要なのか?
背景:増え続ける運用負荷
スタートアップや中小企業では、以下のような課題を抱えています:
- インシデント対応が属人化:障害が発生したとき、「誰が対応するか」が曖昧
- 優先度判断が難しい:新機能開発と品質改善のバランスをどう取るか?
- 経営層への説明が困難:「なぜリリースが遅れるのか」を定量的に説明できない
これらの課題を解決するのが、SLO/エラーバジェットの考え方です。
開発チーム主導のメリット
SREチームがなくても、開発チームが主導でSLO運用を行うことには以下のメリットがあります:
- 早期の問題発見:日々のコードレビューやデプロイ時に品質を意識できる
- コストを抑えた運用:専門チームを雇う前に小さく始められる
- 自律的な改善文化:チーム全体で品質責任を共有し、継続的改善が定着する
SLO設定の基本ステップ
ステップ1:SLI(Service Level Indicator)を定義する
SLIは、サービスの品質を測る具体的な指標です。代表的なSLIとして以下があります:
- 可用性(Availability):リクエストの成功率(例:99.9%)
- レイテンシー(Latency):応答時間(例:95パーセンタイルで500ms以内)
- エラー率(Error Rate):HTTPステータス500系エラーの割合
ステップ2:現状を把握する
まずは現在のサービスがどのくらいの品質で動作しているかを測定します。
# Prometheusでエラー率を取得するクエリ例
error_rate = (
sum(rate(http_requests_total{status=~"5.."}[5m]))
/
sum(rate(http_requests_total[5m]))
) * 100ステップ3:現実的な目標を設定する
重要: 最初から高すぎる目標を設定しないこと。現状が95%の可用性であれば、まずは97%を目指すなど、段階的に向上させます。
| SLI | 現状 | 目標 |
|---|---|---|
| 可用性 | 95.2% | 97.0% |
| レイテンシー(P95) | 800ms | 500ms |
| エラー率 | 2.1% | 1.0% |
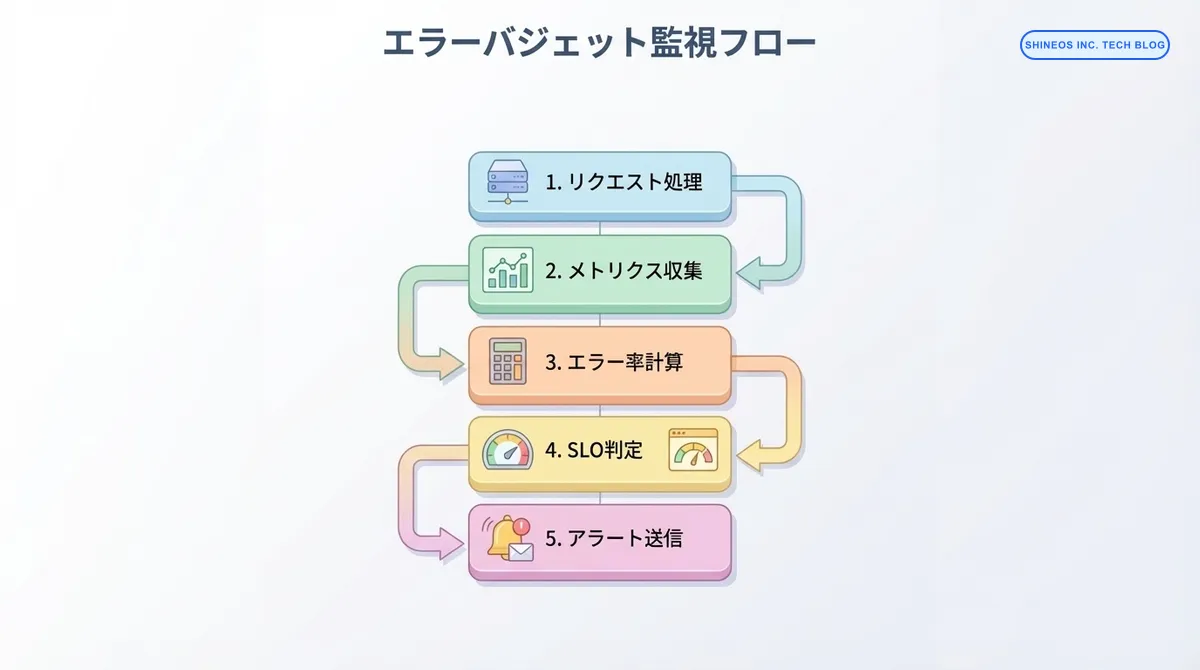
実装例:Prometheus + Grafanaでエラーバジェット監視
環境構築
まず、PrometheusとGrafanaをDocker Composeでセットアップします。
# docker-compose.yml
version: '3.8'
services:
prometheus:
image: prom/prometheus:latest
ports:
- "9090:9090"
volumes:
- ./prometheus.yml:/etc/prometheus/prometheus.yml
- prometheus-data:/prometheus
command:
- '--config.file=/etc/prometheus/prometheus.yml'
- '--storage.tsdb.path=/prometheus'
grafana:
image: grafana/grafana:latest
ports:
- "3000:3000"
environment:
- GF_SECURITY_ADMIN_PASSWORD=admin
volumes:
- grafana-data:/var/lib/grafana
volumes:
prometheus-data:
grafana-data:Prometheusの設定
# prometheus.yml
global:
scrape_interval: 15s
scrape_configs:
- job_name: 'myapp'
static_configs:
- targets: ['localhost:8080']エラーバジェット計算の実装
次に、エラーバジェットを自動計算するPythonスクリプトを作成します。
# error_budget_calculator.py
from datetime import datetime, timedelta
from typing import Dict
class ErrorBudgetCalculator:
def __init__(self, slo_target: float, total_requests: int, failed_requests: int):
"""
Args:
slo_target: SLO目標値(例:99.9 = 99.9%)
total_requests: 総リクエスト数
failed_requests: 失敗したリクエスト数
"""
self.slo_target = slo_target
self.total_requests = total_requests
self.failed_requests = failed_requests
def calculate_error_budget(self) -> Dict:
"""エラーバジェットを計算"""
# 許容される失敗数
allowed_failures = self.total_requests * (1 - self.slo_target / 100)
# 現在のエラー率
current_error_rate = (self.failed_requests / self.total_requests) * 100
# 残りのエラーバジェット
remaining_budget = allowed_failures - self.failed_requests
remaining_budget_percent = (remaining_budget / allowed_failures) * 100
return {
"slo_target": f"{self.slo_target}%",
"current_error_rate": f"{current_error_rate:.2f}%",
"allowed_failures": int(allowed_failures),
"actual_failures": self.failed_requests,
"remaining_budget": int(remaining_budget),
"remaining_budget_percent": f"{remaining_budget_percent:.1f}%",
"status": "HEALTHY" if remaining_budget > 0 else "BUDGET_EXHAUSTED"
}
def can_deploy(self, estimated_failure_rate: float) -> bool:
"""
デプロイ可否を判断
Args:
estimated_failure_rate: デプロイ後の予想失敗率(%)
"""
remaining_budget = self.calculate_error_budget()["remaining_budget"]
estimated_failures = self.total_requests * (estimated_failure_rate / 100)
return remaining_budget > estimated_failures
# 使用例
if __name__ == "__main__":
# 月間1000万リクエスト、現在5000件の失敗
calculator = ErrorBudgetCalculator(
slo_target=99.9,
total_requests=10_000_000,
failed_requests=5_000
)
budget = calculator.calculate_error_budget()
print("=== エラーバジェット レポート ===")
print(f"SLO目標: {budget['slo_target']}")
print(f"現在のエラー率: {budget['current_error_rate']}")
print(f"許容失敗数: {budget['allowed_failures']:,}")
print(f"実際の失敗数: {budget['actual_failures']:,}")
print(f"残りバジェット: {budget['remaining_budget']:,} ({budget['remaining_budget_percent']})")
print(f"ステータス: {budget['status']}")
# デプロイ判断
can_deploy = calculator.can_deploy(estimated_failure_rate=0.05)
print(f"\nデプロイ可否: {'✅ 可能' if can_deploy else '❌ 不可'}")実行結果:
=== エラーバジェット レポート ===
SLO目標: 99.9%
現在のエラー率: 0.05%
許容失敗数: 10,000
実際の失敗数: 5,000
残りバジェット: 5,000 (50.0%)
ステータス: HEALTHY
デプロイ可否: ✅ 可能Grafanaダッシュボード設定
Grafanaで視覚的にエラーバジェットを監視するダッシュボードを構築します。
エラーバジェット残量の可視化
# Grafanaのパネル設定(PromQLクエリ)
# エラーバジェット残量(%)
100 * (
1 - (
sum(increase(http_requests_total{status=~"5.."}[30d]))
/
sum(increase(http_requests_total[30d]))
) / (1 - 0.999)
)このクエリをGrafanaのGaugeパネルに設定することで、リアルタイムでエラーバジェットの残量を監視できます。
実際のビジネスシーンでの活用例
ケース1:リリース判断の定量化
課題: 新機能をリリースしたいが、品質に不安がある。リリース判断をどう行うか?
解決策: エラーバジェットを基準にする
# リリース前のチェック
if calculator.can_deploy(estimated_failure_rate=0.03):
print("✅ エラーバジェットに余裕があります。リリースを進めてください。")
else:
print("❌ エラーバジェットが不足しています。品質改善を優先してください。")ケース2:優先度決定の透明化
課題: 新機能開発と技術的負債の解消、どちらを優先すべきか?
解決策: エラーバジェットの残量で判断
- エラーバジェットが50%以上残っている: 新機能開発にリソースを割ける
- エラーバジェットが20%未満: 品質改善・安定性向上を最優先
ケース3:インシデント対応の効率化
課題: 障害が発生したとき、どの程度の緊急度で対応すべきか不明確
解決策: エラーバジェットの消費速度でトリアージ
def calculate_burn_rate(current_period_failures: int,
period_duration_hours: int) -> float:
"""
エラーバジェット消費速度を計算
Args:
current_period_failures: 現在の期間での失敗数
period_duration_hours: 期間(時間単位)
"""
# 1時間あたりの失敗数
hourly_failure_rate = current_period_failures / period_duration_hours
# 月間での予想失敗数(30日 = 720時間)
monthly_projected_failures = hourly_failure_rate * 720
return monthly_projected_failures
# 使用例
current_failures = 200 # 過去2時間で200件のエラー
burn_rate = calculate_burn_rate(current_failures, period_duration_hours=2)
if burn_rate > 10_000: # 月間許容失敗数を超える場合
print("🚨 緊急対応が必要です!")
elif burn_rate > 5_000:
print("⚠️ 注意が必要です。原因調査を開始してください。")
else:
print("✅ 正常範囲内です。")運用を成功させるためのポイント
1. 小さく始める
最初から完璧なSLO設定を目指さず、以下の順序で段階的に導入します:
- Week 1-2: 可用性SLOのみを設定
- Week 3-4: レイテンシーSLOを追加
- Month 2: エラー率など追加指標を拡充
2. チーム全体で共有する
SLOは開発チームだけでなく、ビジネスチームや経営層とも共有すべき指標です。
- 週次ミーティング: エラーバジェットの残量を報告
- Slackチャンネル: 自動アラートでリアルタイム共有
- 月次レビュー: SLO達成率の振り返りと改善策の議論
3. 自動化を徹底する
手動での監視は継続が困難です。以下のような自動化を導入しましょう:
# Slack通知の実装例
import requests
from typing import Dict
def send_slack_alert(webhook_url: str, budget_info: Dict):
"""エラーバジェット警告をSlackに送信"""
remaining_percent = float(budget_info['remaining_budget_percent'].rstrip('%'))
if remaining_percent < 20:
color = "danger"
message = "🚨 エラーバジェットが残り20%を切りました!品質改善を最優先してください。"
elif remaining_percent < 50:
color = "warning"
message = "⚠️ エラーバジェットが残り50%を切りました。新機能開発よりも安定性向上を検討してください。"
else:
return # アラート不要
payload = {
"attachments": [{
"color": color,
"title": "エラーバジェット アラート",
"text": message,
"fields": [
{"title": "現在のエラー率", "value": budget_info['current_error_rate'], "short": True},
{"title": "残りバジェット", "value": budget_info['remaining_budget_percent'], "short": True},
{"title": "実際の失敗数", "value": f"{budget_info['actual_failures']:,}", "short": True},
{"title": "許容失敗数", "value": f"{budget_info['allowed_failures']:,}", "short": True}
]
}]
}
requests.post(webhook_url, json=payload)
# 使用例
webhook_url = "https://hooks.slack.com/services/YOUR/WEBHOOK/URL"
send_slack_alert(webhook_url, budget)よくある質問
SLOは何%に設定すべきですか?
一概に「この数字が正解」というものはありませんが、目安としては以下がよく使われます。
- 社内向けツール:95〜97%
- 一般的なWebサービス:99.0〜99.5%
- ミッションクリティカルなサービス:99.9〜99.99%
ただし、最初から高い数値を掲げることが必ずしも良いとは限りません。
大切なのは、いまの実測値を基準にすることです。
たとえば現在の達成率が95%前後であれば、まずは97%を安定して達成することを目標にします。
運用を回しながら段階的に引き上げていくほうが、現実的で継続しやすいケースが多いです。
エラーバジェットを使い切った場合、どう対応すべきですか?
エラーバジェットを使い切ったこと自体は「失敗」ではありません。あらかじめ想定していたリスクが、実際に顕在化したというサインです。
一般的には、次のような対応を取ります。
- 新機能リリースを一時的に抑制
まずは機能追加よりも安定性の回復を優先します。 - 原因の振り返り
特定の変更や運用フローに問題がなかったかを確認します。 - 再発防止策の整理
すぐに直せるものと、中長期で対応すべきものを切り分けます。
このサイクルを回すことで、SLOは「守るためのルール」ではなく、改善を進めるための判断材料として機能します。
SREチームがなくても運用は可能ですか?
可能です。実際、小規模チームやスタートアップでは専任のSREを置かずに運用している例も多くあります。 その場合、以下の点を意識すると現実的に回ります。
- 監視・可視化はツールに任せる
Prometheus、Grafana、Datadog などを使い、状況を数字で把握できる状態にします。 - 短時間でも定期的に振り返る
週1回、30分程度でも十分です。数字を見て「何が起きたか」を共有します。 - SLOをチーム共通の言葉にする
運用担当だけでなく、開発メンバーもSLOを前提に判断できる状態が理想です。
無理に体制を大きくするよりも、仕組みと合意形成を整えるほうが効果的なことも少なくありません。
おわりに
SLO/エラーバジェット運用は、SREチームがいなくても開発チームだけで十分に実践可能な手法です。重要なのは、完璧を求めず、小さく始めて継続的に改善する ことです。
まずは可用性のSLOを1つ設定し、1ヶ月間運用してみてください。チームの意識が変わり、品質に対する共通言語が生まれるはずです。
私たちShineosでは、SLO/エラーバジェット運用の導入支援や、開発チーム向けのSRE教育プログラムを提供しています。運用自動化の仕組みづくりやチーム文化の醸成など、お気軽にご相談ください。