
Prometheus運用で「アラートオオカミ少年」にならないための、Shineos流実践的Alertmanager設定術
この記事の要点
Q: アラート疲労の主な原因は何ですか?
Q: route設定の鉄則は?
Q: 深夜の不要なアラートをどう防ぎますか?
はじめに
この記事は、Zennで公開した記事「 【監視入門】PrometheusとGrafanaで「障害に気づけない」恐怖から解放される 」の 実践・詳細編(Part 2) です。
入門編では、Docker Composeを使ってとりあえず「監視できる環境」を作りました。しかし、そのまま本番運用を始めると、高い確率で 「アラート通知が鳴りすぎて、誰も見なくなる」 という事態に陥ります。
本記事では、Prometheusの相棒であるAlertmanagerを使いこなし、健全な運用を取り戻すための具体的な設定テクニックを紹介します。
Alertmanagerとは?
Prometheusが検知したアラートを受け取り、整理整頓してからSlackやメールなどに通知する「司令塔」のようなコンポーネントです。
主な役割
- 重複排除 (Deduplication): 同じアラートを何度も通知しない。
- グループ化 (Grouping): 関連するアラートをまとめて1通の通知にする。
- ルーティング (Routing): 重要度や種類に応じて通知先(Slackチャンネルなど)を振り分ける。
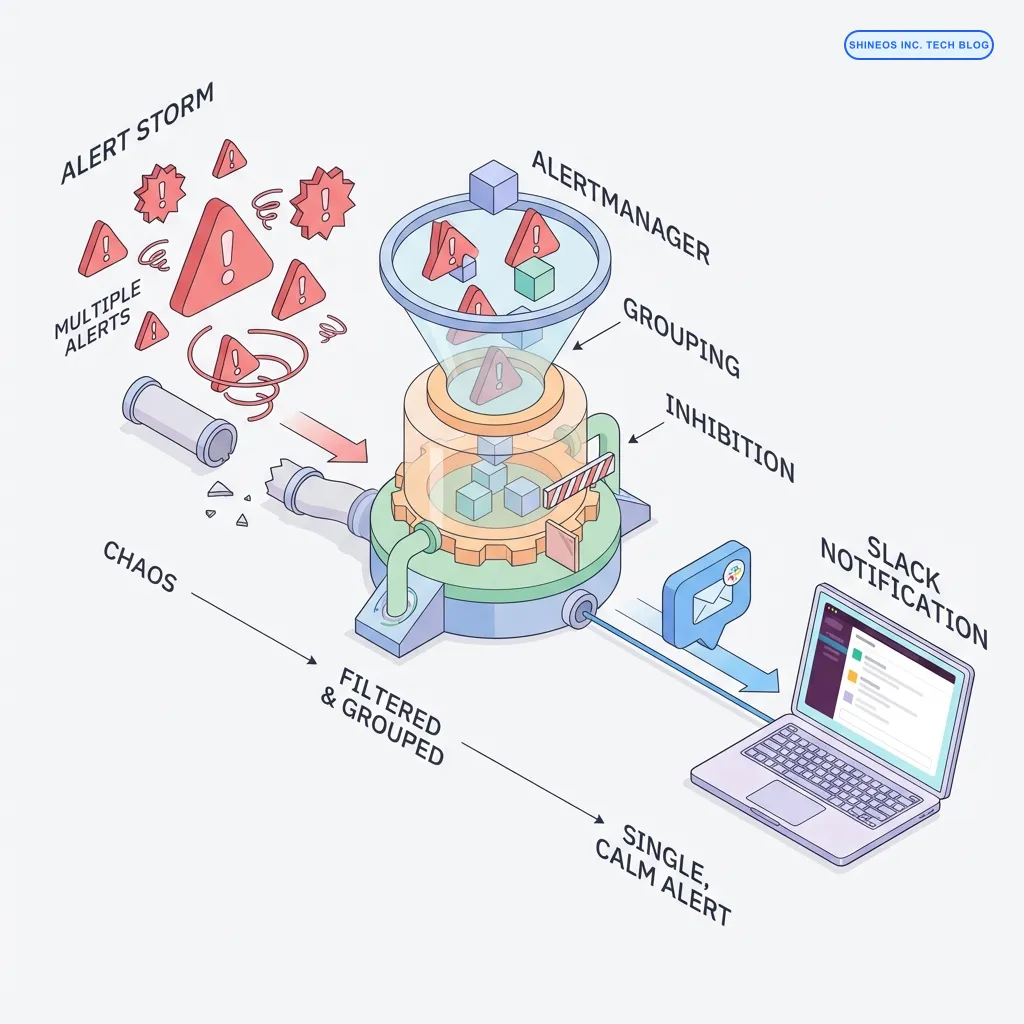
まとめ
本記事で解説する「オオカミ少年化」を防ぐポイントは以下の通りです。
- Grouping: 大量のアラートを「サービス単位」や「深刻度単位」で1つにまとめる。
- Inhibition: 「サーバーダウン」が出たら「CPU使用率」のアラートは止める(原因が同じなら根本だけ通知)。
- Silencing: 計画メンテナンス中や既知のバグ対応中は、特定の通知を一時的にミュートする。
なぜ「アラートオオカミ少年」になってしまうのか
監視を始めたばかりのチームでよくあるのが、**「とりあえず全部通知する」**という設定です。
例えば、10台のサーバーで同時にネットワーク障害が起きたとします。適切な設定がない場合、10台 × 複数のメトリクス(Ping切れ、HTTPエラーなど)で、一瞬にして 数十〜数百件の通知 がSlackに爆撃されます。
こうなると、エンジニアは通知を「ミュート」し始めます。そして、そのミュートされた通知の中に、本当に重要な「データベース停止」のアラートが埋もれてしまうのです。これが「アラートオオカミ少年」の正体であり、絶対に避けなければならない状態です。
以前、私が担当したプロジェクトでは、開発環境のPod再起動アラートを放置していた結果、本番環境での重要なメモリリーク警告を見落とし、深夜に緊急対応する羽目になりました。「重要でない通知」は「ノイズ」であり、ノイズは運用者の判断力を奪います。
Shineos流:実践的Alertmanager設定
私たちが推奨する、最小限かつ効果的な alertmanager.yml の構成例を紹介します。
1. ディレクトリ構造とファイルの準備
入門編の monitoring-handson ディレクトリに、新たに alertmanager 用の設定を追加します。
touch alertmanager.yml2. alertmanager.yml の設定
以下の設定では、Slackへの通知を例に、「重要度(severity)」で通知先を振り分け、かつ無駄な連送を防ぐ設定を入れています。
global:
resolve_timeout: 5m
slack_api_url: 'YOUR_SLACK_WEBHOOK_URL' # 実際のURLに置き換えてください
route:
group_by: ['alertname', 'severity'] # アラート名と重要度でまとめる
group_wait: 30s # 最初のアラートから30秒は他のアラートを待つ(まとめ待ち)
group_interval: 5m # 同じグループのアラートが続いている場合、5分おきに通知
repeat_interval: 4h # 同じアラートが解決していない場合、4時間おきに再通知
receiver: 'slack-notifications' # デフォルトの通知先
# ルーティング設定
routes:
# critical(重度)はメンション付きで即通知したい場合などの設定
- match:
severity: 'critical'
receiver: 'slack-priority'
group_wait: 10s # 緊急なので待ち時間を短く
receivers:
- name: 'slack-notifications'
slack_configs:
- channel: '#alerts'
send_resolved: true
title: '[{{ .Status | toUpper }}] {{ .CommonLabels.alertname }}'
text: >-
{{ range .Alerts }}
*Alert:* {{ .Annotations.summary }}
*Description:* {{ .Annotations.description }}
*Details:*
{{ range .Labels.SortedPairs }} • *{{ .Name }}:* `{{ .Value }}`
{{ end }}
{{ end }}
- name: 'slack-priority'
slack_configs:
- channel: '#alerts-urgent' # 緊急用チャンネル
send_resolved: true
title: '<!channel> 🚨 [{{ .Status | toUpper }}] {{ .CommonLabels.alertname }}'
text: "{{ range .Alerts }}Critical Alert: {{ .Annotations.description }}{{ end }}"注意:
YOUR_SLACK_WEBHOOK_URL は必ずご自身のSlack Incoming Webhook URLに書き換えてください。
3. Docker Composeへの追加
docker-compose.yml に Alertmanager を追加し、Prometheusと連携させます。
# 前回の内容に追記
services:
# ... (prometheus, grafana, node-exporter) ...
alertmanager:
image: prom/alertmanager:latest
container_name: alertmanager
volumes:
- ./alertmanager.yml:/etc/alertmanager/alertmanager.yml
ports:
- "9093:9093"
networks:
- monitoring
prometheus:
# ...
command:
- '--config.file=/etc/prometheus/prometheus.yml'
- '--storage.tsdb.path=/prometheus'
- '--web.console.libraries=/usr/share/prometheus/console_libraries'
- '--web.console.templates=/usr/share/prometheus/consoles'
# Alertmanagerとの連携設定を追加(コマンド引数が上書きされるため、全体を記述する必要があります)
volumes:
- ./prometheus.yml:/etc/prometheus/prometheus.yml
# 連携設定のため、prometheus.yml側にも追記が必要です(後述)※ prometheus.yml にも以下の追記が必要です。
# 追記
alerting:
alertmanagers:
- static_configs:
- targets: ['alertmanager:9093']
rule_files:
- "alert_rules.yml" # アラートルールファイル(別途作成が必要)本番環境での知見:
group_wait を 30s に設定しているのは、一時的なスパイクによる誤検知(Flapping)を通知しないためのフィルターとしても機能します。CPU使用率が一瞬100%になっても、30秒以内に戻れば通知されません。これでかなりの「オオカミ少年」を防げます。
もう一つの武器:Silencing(サイレンシング)
設定ファイルを書かなくても、GUIから一時的に通知を止めることができるのが Silencing です。
- 計画メンテナンス: 「今からデプロイするから深夜2:00〜2:30のアラートは無視してほしい」
- 既知の不具合: 「この警告はバグだと分かっていて対応中だから、修正されるまで通知しないで」
これらは Alertmanager のUI(http://localhost:9093)から直感的に設定できます。「New Silence」ボタンを押し、期間と条件(例: instance="db-server-01")を指定するだけです。
よくある質問
Q. アラートの閾値はどう決めるべきですか?
最初から完璧な値は決められません。まずは「少し緩め」に設定し、運用しながら徐々に厳しくしていく(またはその逆)のが現実的です。Shineosでは、「ユーザー影響が出ているか?」を最優先基準にしています。
Q. Alertmanagerがダウンしたらどうなりますか?
通知が届かなくなります。そのため、本番環境では Alertmanager を複数台構成(高可用性構成)にするのが一般的です。Gossipプロトコルで通信し合い、重複通知を防ぎながら冗長化できます。
おわりに
監視システムは、「アラートを鳴らすこと」が目的ではなく、「システムの健康状態を維持し、万が一の際に迅速に復旧させること」が目的です。
通知が多すぎると、私たちは無意識にそれを無視し始めます。今回紹介したGroupingやSilencingを駆使して、「通知が来たら、それは本当に今すぐ対応すべきことだ」とチーム全員が信じられる状態を作ってください。
私の使い方は、開発初期はあえて通知を多めにしてシステムの挙動を把握し、安定稼働に入ったら容赦なく不要なアラートを削ぎ落とすスタイルです。静かなSlackチャンネルこそが、平和なシステムの証ですから。
最後になりますが、私たちShineosでは、このような実践的なSRE/DevOpsの知見を活かした SaaSプロダクト開発支援 を行っています。「監視基盤の構築に手が回らない」「運用コストを下げたい」という課題をお持ちの方は、ぜひお気軽にご相談ください。