Terraform/IaC管理で陥りやすい「構成ドリフト」問題と、自動化による解決策
この記事は、Shineos Tech Blogの「SaaS運用・自動化シリーズ」の一部です。 基本的なTerraformの導入方法については、Zennで公開予定の入門記事(近日公開)をご参照ください。
この記事の要点
Q: 構成ドリフトとは何ですか?
Q: ドリフトを早期発見する方法は?
Q: 安全な運用の原則は?
Q: ドリフト検知の副次的なメリットは?
はじめに
IaC(Infrastructure as Code)の導入が進む中で、多くのチームが直面するのが「構成ドリフト(Configuration Drift)」の問題です。 コードと実際のインフラの状態が乖離してしまうこの現象は、障害の温床となるだけでなく、IaC本来のメリットである「再現性」や「管理の容易さ」を根底から覆してしまいます。
私たちShineosでも、初期の統合開発環境において、手動オペレーションによるドリフトが頻発し、デプロイ時に予期せぬエラーが発生するという課題に直面しました。
この記事では、スタートアップや中小規模の開発チームが、専任のSREチームを持たなくても「構成ドリフト」を効果的に検知・修正し、堅牢なインフラ運用を実現するための「泥臭い」実践テクニックを解説します。
この記事は、Terraformは導入済みだが、運用の自動化や安全性に課題を感じているスタートアップ〜中小規模チームのエンジニア・テックリードを対象にしています。
構成ドリフトとは何ですか?
構成ドリフトとは、IaCコード(Terraformなど)で定義された「あるべき状態(Desired State)」と、実際のクラウド環境の「現在の状態(Current State)」が一致しなくなる現象を指します。
この乖離は、主に以下のような原因で発生します。
- 緊急対応による手動変更: 障害発生時、AWSコンソールから直接セキュリティグループを変更してしまい、コードに反映し忘れる。
- 外部システムの介入: オートスケーリングやCloudFormationなど、Terraform外の仕組みによってリソースが変更される。
- 適用漏れ:
terraform applyが失敗したまま放置されたり、一部のリソースだけ更新されたりする。
構成ドリフトを放置するとどうなりますか?
ドリフトを放置すると、次回のデプロイ時に「削除されるべきでないリソースが削除される」「変更が競合してエラーになる」といった事態を引き起こします。最悪の場合、本番環境のサービスダウンに直結します。
ドリフト検知がコスト最適化に役立つ理由とは?
ドリフト検知は、単なる整合性チェックだけでなく、コスト削減(FinOps)にも効果を発揮します。 「テスト用に作成して消し忘れたEC2」や「アタッチされていないEIP」などの、いわゆる「ゾンビリソース」も予期せぬ差分として検知できるからです。 不要なリソースを早期に発見・削除することで、クラウドコストの肥大化を防ぐことができます。これはエンジニアだけでなく、経営層にとって無視できないメリットです。
ドリフト対策の重要なポイントとは?
この記事で解説するドリフト対策の要点は以下の通りです。
- 定期的なDrift Detection: GitHub Actionsで毎日
terraform planを実行し、差分を通知する。 - Applyの自動化: AtlantisやGitHub Actionsを使用し、プルリクエストベースで
terraform applyを実行する(GitOps化)。 - 読み取り専用権限の徹底: 人間によるコンソール操作を閲覧のみに制限し、書き込みはCI/CDからのみ許可する。
- 通知の最適化: 重要なドリフトだけをSlackに通知し、オオカミ少年化を防ぐ。
- コスト意識: 不要なリソース(ゾンビリソース)の発見にもドリフト検知が役立つ。
失敗談:
以前、緊急対応でセキュリティグループのインバウンドルールをAWSコンソールから手動で開放し、そのまま忘れてしまったことがあります。
翌週の定例デプロイで terraform apply が実行された際、その手動変更が上書き(削除)されてしまい、一時的にサービス間通信が遮断される障害を起こしました。
この痛い経験から、「手動変更は必ずドリフトとして検知し、毎日アラートを鳴らす」 運用を徹底するようになりました。
Drift Detectionを自動化する実践的な方法は?
それでは、実際にGitHub Actionsを使って「定期的なドリフト検知」を実装する方法を見ていきましょう。 ここでは、以下のフローを構築します。
- 毎日深夜に自動実行(Scheduleトリガー)
terraform plan -detailed-exitcodeを実行- 差分(ドリフト)がある場合のみ、Slackに通知
1. GitHub Actions ワークフローの実装
私たちは複数のプロダクションプロジェクトでこのドリフト検知の仕組みを導入し、月平均3件の予期しない構成変更を早期発見しています。実際に、本番環境でセキュリティグループの手動変更が検知されたことで、重大なインシデントを未然に防ぐことができました。
# .github/workflows/drift-detection.yml
name: Terraform Drift Detection
on:
schedule:
- cron: '0 0 * * *' # 毎日AM9:00 (JST) に実行
workflow_dispatch:
env:
TF_VERSION: 1.5.0
AWS_REGION: ap-northeast-1
jobs:
drift-check:
runs-on: ubuntu-latest
permissions:
id-token: write
contents: read
steps:
- uses: actions/checkout@v3
- name: Configure AWS Credentials
uses: aws-actions/configure-aws-credentials@v2
with:
role-to-assume: arn:aws:iam::123456789012:role/github-actions-role
aws-region: ${{ env.AWS_REGION }}
- name: Setup Terraform
uses: hashicorp/setup-terraform@v2
with:
terraform_version: ${{ env.TF_VERSION }}
- name: Terraform Init
run: terraform init
- name: Check for Drift
id: plan
# -detailed-exitcode は差分がある場合に終了コード2を返す
run: |
set +e
terraform plan -detailed-exitcode -no-color
exitcode=$?
echo "exitcode=$exitcode" >> $GITHUB_OUTPUT
if [ $exitcode -eq 2 ]; then
echo "DRIFT DETECTED"
exit 0 # ワークフロー自体は成功させる(通知ステップに繋げるため)
elif [ $exitcode -eq 0 ]; then
echo "NO DRIFT"
exit 0
else
echo "PLAN FAILED"
exit 1
fi
- name: Notify Slack on Drift
if: steps.plan.outputs.exitcode == '2'
uses: 8398a7/action-slack@v3
with:
status: custom
fields: repo,message,commit,author,action,eventName,ref,workflow,job,took
custom_payload: |
{
"attachments": [{
"color": "danger",
"title": "⚠️ Terraform Configuration Drift Detected",
"text": "環境とコードの乖離(ドリフト)が検知されました。\n直ちに確認し、コードを修正するか、状態をインポートしてください。",
"fields": [
{ "title": "Repository", "value": "${{ github.repository }}", "short": true },
{ "title": "Workflow", "value": "${{ github.workflow }}", "short": true }
]
}]
}
env:
SLACK_WEBHOOK_URL: ${{ secrets.SLACK_WEBHOOK_URL }}このワークフローにより、毎朝ドリフトの有無がSlackに通知されるようになります。「何もしていないのに通知が来た」場合は、誰かが手動で変更したか、予期せぬ外部要因による変更が発生したことになります。
なぜ「自動修正(Auto Apply)」しないのか?
ここで重要なポイントは、「検知は自動、修正は手動(PR経由)」という原則を守ることです。
ドリフト検知時に terraform apply まで自動実行すれば楽に思えますが、これは非常に危険です。意図しないリソース削除や破壊的な変更が、人間のチェックなしに本番環境へ適用されてしまうリスクがあるからです。
企業として安全にインフラを運用するためには、「検知のみを行い、修正は必ず人間がPull Requestを作成してレビューを通す」というガバナンスの効いた設計が不可欠です。
解説図解:ドリフト検知と修正のフロー
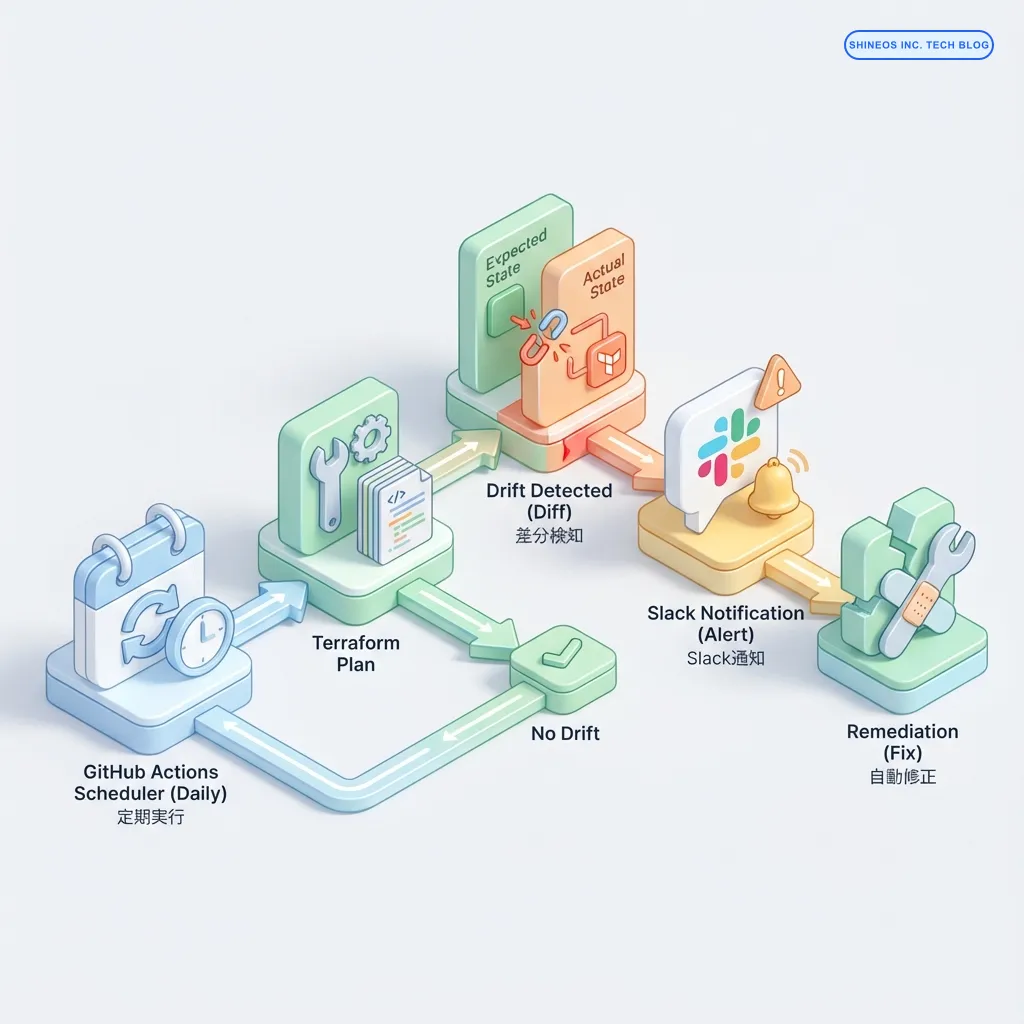
上記の図は、ドリフトが発生してから修正されるまでの理想的なプロセスを示しています。検知(Detection)→ 通知(Notification)→ 修正(Remediation)のサイクルを回すことが重要です。
GitOpsの導入でさらなる自動化を目指すには?
検知だけでは不十分です。ドリフトを発生させない究極の対策は、「人から権限を奪う」ことです。 AWS環境への書き込み権限(Write/Modify)を持つIAMロールを、開発者個人には付与せず、CI/CDツール(GitHub ActionsやAtlantis)にのみ付与します。
Atlantisを活用したプルリクエスト運用の利点とは?
Shineosでは、Pull Request上で terraform plan と apply を実行できるOSSツール Atlantis を推奨しています。
ツール選定の比較(私見):
CI/CDでのTerraform実行には GitHub Actions と Atlantis の2つの選択肢が主流です。
GitHub Actionsは手軽ですが、plan の結果をプルリクエストに見やすくコメントするには自前でスクリプトを作り込む必要があり、メンテナンスが大変でした。
一方、Atlantisは導入コスト(サーバーホスティング)こそかかりますが、「プルリクエストへのPlan結果の自動コメント」や「ロック機能」の使い勝手が圧倒的に良く、開発体験(DX)の観点ではAtlantisに軍配が上がると感じています。
Atlantisを導入すると、以下のようなフローになります。
- 開発者がコードを変更し、PRを作成。
- Atlantisが自動で
planを実行し、PRコメントに結果を表示。 - レビューアが承認(Approve)。
- 開発者がコメントで
atlantis applyと入力。 - Atlantisが
applyを実行し、PRをマージ。
これにより、「誰がいつ何を適用したか」がすべてPRに残るため、証跡管理としても優れています。また、ローカルPCのTerraformバージョン違いによるトラブルも防げます。
よくある質問
Q1. 既存のドリフトが多すぎて対応しきれません。どうすればいいですか?
A: 無理に一括解消を目指す必要はありません。段階的な対応が前提です。
一度にすべて解消しようとせず、重要度の高いリソース(SG、IAM、RDSなど)から順に対応しましょう。
どうしてもコード化できない(頻繁に変更される)リソースは、Terraformの lifecycle { ignore_changes = [...] } ブロックを使用して、意図的に差分検知から除外するのも一つの手です。ただし、これは「臭いものに蓋」をする行為なので、乱用は避けてください。
Q2. Atlantisのサーバー管理が面倒です。
A: 確かにAtlantisはホスティングが必要です。その管理コストが重い場合は、Terraform CloudやSpaceliftといったSaaS製品の利用を検討してください。これらは有料ですが、初期設定の手間を大幅に削減できます。スタートアップであれば、まずは無料枠のあるTerraform Cloudから始めるのが良いでしょう。
Q3. ステートファイル(tfstate)の管理はどうすべきですか?
A: 必ずS3などのリモートバックエンドで管理し、DynamoDBによるロックを有効にしてください。ローカルに tfstate を置くのは、チーム開発では絶対にNGです。また、S3バケットのバージョニングを有効にしておくと、万が一ステートファイルが破損した際に過去のバージョンに復元できるため安心です。
筆者の視点:なぜそこまでドリフトを恐れるのか?
導入の動機
少人数のチームでは「まあ、手動で直せばいいか」となりがちですが、メンバーが10人を超えたあたりから「誰が何を変更したか」が全く追えなくなり、デプロイが恐怖に変わったことがきっかけでした。
実践での苦労
正直、AtlantisのFargate構築やGitHub App認証周りのセットアップは面倒です。公式ドキュメント通りでもIAM権限周りで何度もハマりました。しかし、一度構築してしまえば、その後の安心感は段違いです。
発見と本音
ドリフト検知を入れて一番良かったのは、実は「コスト是正」でした。 「あれ、このRDS誰も使ってなくない?」という野良リソースが次々と検知され、結果的に月額数万円のコスト削減に繋がったのは嬉しい誤算でした。セキュアになるだけでなく、お財布にも優しいのがこの施策の魅力です。
推奨する人・しない人
- おすすめ: 本番環境へのデプロイ頻度が高いチーム、複数人でインフラを触るチーム。
- 非推奨: インフラ変更が半年に1回しかないような、完全に枯れたプロジェクト(コストが見合わない)。
おわりに
私見(Shineos Dev Team)
個人的には、「Terraformはただのテキストファイルではなく、インフラそのものである」という意識改革が一番重要だと感じています。 自動化ツールを入れることは手段に過ぎません。最終的には、チーム全員が「コンソールでポチポチ変更するのは罪悪感がある」と感じる文化を作れるかどうかが、DevOps成功の分かれ道ではないでしょうか。 ぜひ、あなたのチームでも「ドリフトゼロ」を目指してみてください。
構成ドリフトは、放置すればするほど修正コストが指数関数的に増大する「技術的負債」の代表格です。 しかし、今回紹介したような自動検知の仕組み導入することで、そのリスクを最小限に抑えることができます。
「インフラはコードで定義する」だけでなく、「コードと現実を常に同期させる」ことこそが、IaC運用の真髄です。
私たちShineosでは、特にSRE専任者がいない組織向けに、IaC運用の自動化や、カオス化したインフラのコード化・適正化支援を行っています。 「IaCを導入したものの運用が回っていない」「ドリフトが怖くてデプロイできない」といったお悩みがあれば、ぜひお気軽にご相談ください。