LangChainとLangGraphで実現するマルチエージェントシステム
はじめに
この記事の要点
Q: マルチエージェントシステムとは何ですか?
Q: LangGraphの役割は何ですか?
Q: 役割分担のメリットは何ですか?
Q: Human-in-the-loopとは何ですか?
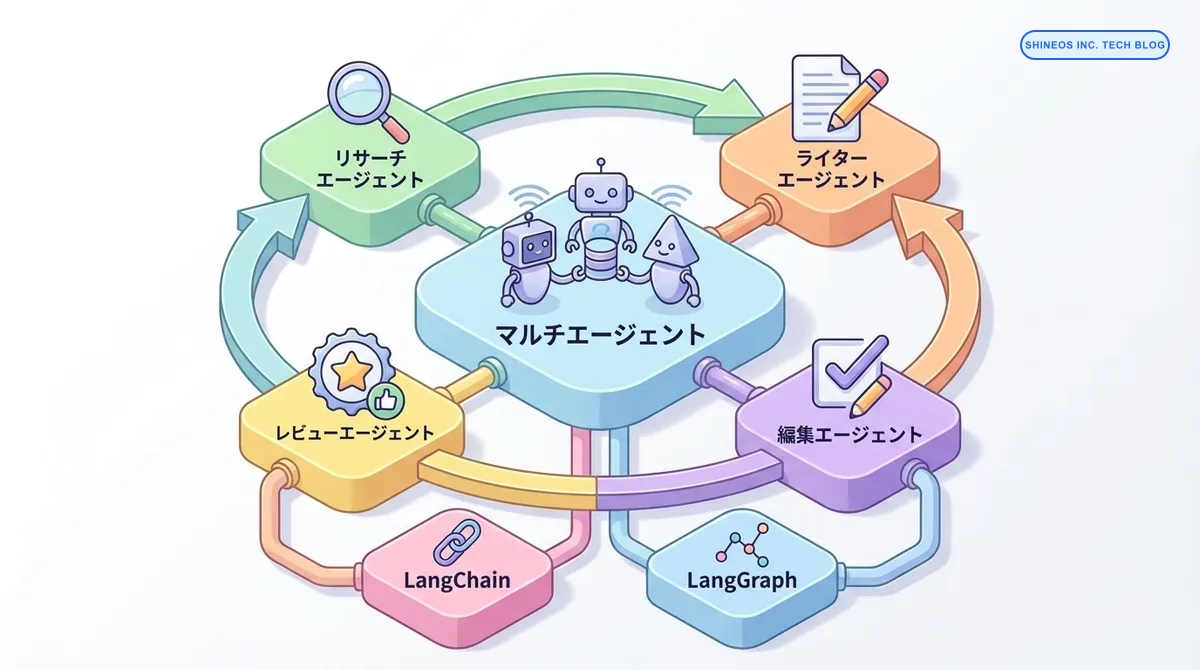
AIエージェントの活用が進む中、注目を集めているのが「複数のエージェントを協調させる」マルチエージェントシステムです。単一のLLMに全ての指示を出すのではなく、専門性の高いエージェントを組み合わせることで、より高度なタスクを安定して遂行できるようになります。
この記事では、LangChainエコシステムの強力なライブラリである LangGraph を活用し、実務で使えるマルチエージェントシステムを構築する方法を詳しく解説します。
マルチエージェントシステムとはどのようなものですか?
マルチエージェントシステムとは、特定の役割を与えられた複数の AI エージェントが、互いに情報を交換し、協力して一つの目標を達成する仕組みです。人間がチームで働く際、リーダー、エンジニア、デザイナー、レビュアーがそれぞれの専門性を発揮するのと同様の構造を AI で実現します。
単一エージェント vs マルチエージェント
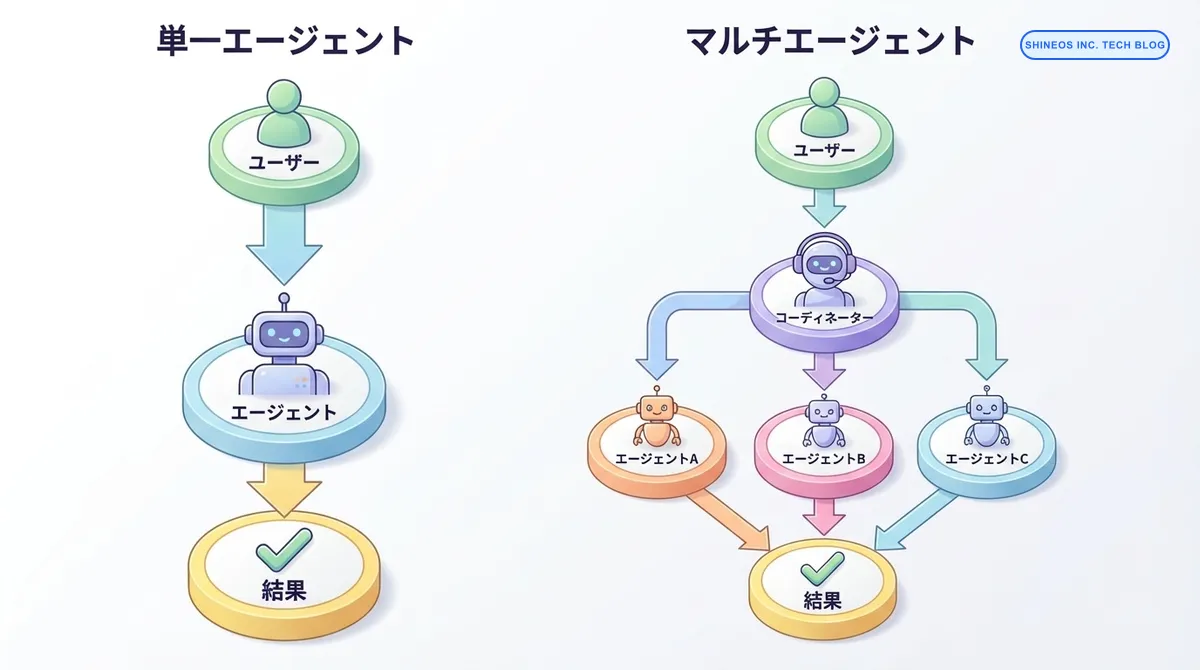
単一エージェントは、ユーザーからの入力を1つのエージェントが処理して結果を返すシンプルな構造です。
一方、マルチエージェントでは、コーディネーターが複数の専門エージェント(A、B、C)にタスクを分配し、それぞれの結果を統合して最終的な回答を生成します。この構造により、複雑なタスクを効率的に処理できます。
まとめ
| 項目 | 説明 | メリット |
|---|---|---|
| 役割分担 | 各エージェントが専門タスクを担当 | 効率性と精度の向上 |
| 協調動作 | エージェント間で情報を共有 | 複雑なタスクの分解と並列処理 |
| LangChain | エージェントの構築とツール連携 | 豊富なツールとインテグレーション |
| LangGraph | エージェント間のワークフロー制御 | 柔軟な状態管理とフロー設計 |
| 適用例 | リサーチ、コンテンツ作成、データ分析 | 業務自動化の高度化 |
LangChainとLangGraphの基礎
LangChainとは
LangChainは、LLMアプリケーションの開発を支援するフレームワークです。エージェント、ツール、メモリーなどの抽象化により、複雑なAIシステムを効率的に構築できます。
from langchain.agents import AgentExecutor, create_openai_functions_agent
from langchain.tools import tool
from langchain_openai import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
# ツールの定義
@tool
def search_database(query: str) -> str:
"""データベースから情報を検索する"""
# 実際の検索ロジック
return f"検索結果: {query}に関する情報"
# LLMの初期化
llm = ChatOpenAI(model="gpt-4o", temperature=0)
# プロンプトテンプレート
prompt = ChatPromptTemplate.from_messages([
("system", "あなたは親切なアシスタントです。"),
("human", "{input}"),
("placeholder", "{agent_scratchpad}"),
])
# エージェントの作成
agent = create_openai_functions_agent(
llm=llm,
tools=[search_database],
prompt=prompt
)
# エージェント実行器
agent_executor = AgentExecutor(
agent=agent,
tools=[search_database],
verbose=True
)
# 実行
result = agent_executor.invoke({"input": "最新の売上データを教えて"})LangGraphとは
LangGraphは、複雑な状態を持つエージェントワークフローを構築するためのライブラリです。グラフベースでエージェントの動作フローを定義できます。
from langgraph.graph import StateGraph, END
from typing import TypedDict, Annotated
import operator
# 状態の定義
class AgentState(TypedDict):
messages: Annotated[list, operator.add]
current_agent: str
task_result: dict
# グラフの作成
workflow = StateGraph(AgentState)
# ノード(処理)の追加
def coordinator_node(state: AgentState):
"""コーディネーターノード"""
# タスクを分析して次のエージェントを決定
next_agent = determine_next_agent(state["messages"][-1])
return {"current_agent": next_agent}
def agent_a_node(state: AgentState):
"""エージェントAの処理"""
result = agent_a.invoke(state["messages"])
return {"messages": [result], "task_result": {"agent_a": result}}
workflow.add_node("coordinator", coordinator_node)
workflow.add_node("agent_a", agent_a_node)
# エッジ(遷移)の追加
workflow.add_edge("coordinator", "agent_a")
workflow.add_edge("agent_a", END)
# エントリーポイントの設定
workflow.set_entry_point("coordinator")
# コンパイル
app = workflow.compile()
# 実行
result = app.invoke({"messages": ["タスクを実行して"], "current_agent": "", "task_result": {}})マルチエージェントシステムの設計パターン
パターン1: 順次実行パターン
エージェントが順番にタスクを処理するシンプルなパターンです。
from langgraph.graph import StateGraph, END
from typing import TypedDict
class SequentialState(TypedDict):
input: str
research_result: str
draft_result: str
final_result: str
def research_agent(state: SequentialState):
"""リサーチエージェント"""
research_prompt = f"以下のトピックについて調査してください: {state['input']}"
result = llm.invoke(research_prompt)
return {"research_result": result.content}
def writer_agent(state: SequentialState):
"""ライターエージェント"""
write_prompt = f"""
以下の調査結果を基に記事を作成してください:
{state['research_result']}
"""
result = llm.invoke(write_prompt)
return {"draft_result": result.content}
def editor_agent(state: SequentialState):
"""編集者エージェント"""
edit_prompt = f"""
以下の記事を校正・改善してください:
{state['draft_result']}
"""
result = llm.invoke(edit_prompt)
return {"final_result": result.content}
# ワークフローの構築
workflow = StateGraph(SequentialState)
workflow.add_node("research", research_agent)
workflow.add_node("writer", writer_agent)
workflow.add_node("editor", editor_agent)
workflow.add_edge("research", "writer")
workflow.add_edge("writer", "editor")
workflow.add_edge("editor", END)
workflow.set_entry_point("research")
sequential_app = workflow.compile()
# 実行
result = sequential_app.invoke({
"input": "AIエージェントの最新トレンド",
"research_result": "",
"draft_result": "",
"final_result": ""
})
print(result["final_result"])パターン2: 並列実行パターン
複数のエージェントが同時にタスクを処理し、結果を統合するパターンです。
from typing import List
class ParallelState(TypedDict):
input: str
analysis_results: List[dict]
final_summary: str
def market_analyst(state: ParallelState):
"""市場分析エージェント"""
prompt = f"市場トレンドを分析: {state['input']}"
result = llm.invoke(prompt)
return {"analysis_results": [{"type": "market", "content": result.content}]}
def competitor_analyst(state: ParallelState):
"""競合分析エージェント"""
prompt = f"競合他社を分析: {state['input']}"
result = llm.invoke(prompt)
return {"analysis_results": [{"type": "competitor", "content": result.content}]}
def tech_analyst(state: ParallelState):
"""技術分析エージェント"""
prompt = f"技術動向を分析: {state['input']}"
result = llm.invoke(prompt)
return {"analysis_results": [{"type": "technology", "content": result.content}]}
def synthesizer(state: ParallelState):
"""統合エージェント"""
analyses = "\n\n".join([
f"【{a['type']}】\n{a['content']}"
for a in state['analysis_results']
])
prompt = f"""
以下の分析結果を統合して総合レポートを作成してください:
{analyses}
"""
result = llm.invoke(prompt)
return {"final_summary": result.content}
# 並列ワークフローの構築
parallel_workflow = StateGraph(ParallelState)
# 並列実行するノードを追加
parallel_workflow.add_node("market", market_analyst)
parallel_workflow.add_node("competitor", competitor_analyst)
parallel_workflow.add_node("tech", tech_analyst)
parallel_workflow.add_node("synthesizer", synthesizer)
# 並列実行の設定
parallel_workflow.set_entry_point("market")
parallel_workflow.set_entry_point("competitor")
parallel_workflow.set_entry_point("tech")
# すべての並列ノードから統合ノードへ
parallel_workflow.add_edge("market", "synthesizer")
parallel_workflow.add_edge("competitor", "synthesizer")
parallel_workflow.add_edge("tech", "synthesizer")
parallel_workflow.add_edge("synthesizer", END)
parallel_app = parallel_workflow.compile()パターン3: 条件分岐パターン
状態に応じて動的にエージェントの実行フローを切り替えるパターンです。
class ConditionalState(TypedDict):
query: str
query_type: str
result: str
def classifier_agent(state: ConditionalState):
"""分類エージェント"""
prompt = f"""
以下の質問を分類してください。
- 'technical': 技術的な質問
- 'business': ビジネスに関する質問
- 'general': 一般的な質問
質問: {state['query']}
分類(technical/business/generalのいずれか):
"""
result = llm.invoke(prompt)
return {"query_type": result.content.strip().lower()}
def technical_agent(state: ConditionalState):
"""技術専門エージェント"""
prompt = f"技術的な観点から回答: {state['query']}"
result = llm.invoke(prompt)
return {"result": result.content}
def business_agent(state: ConditionalState):
"""ビジネス専門エージェント"""
prompt = f"ビジネスの観点から回答: {state['query']}"
result = llm.invoke(prompt)
return {"result": result.content}
def general_agent(state: ConditionalState):
"""一般エージェント"""
prompt = f"一般的な観点から回答: {state['query']}"
result = llm.invoke(prompt)
return {"result": result.content}
def route_query(state: ConditionalState):
"""ルーティング関数"""
query_type = state.get("query_type", "general")
if query_type == "technical":
return "technical"
elif query_type == "business":
return "business"
else:
return "general"
# 条件分岐ワークフローの構築
conditional_workflow = StateGraph(ConditionalState)
conditional_workflow.add_node("classifier", classifier_agent)
conditional_workflow.add_node("technical", technical_agent)
conditional_workflow.add_node("business", business_agent)
conditional_workflow.add_node("general", general_agent)
# エントリーポイント
conditional_workflow.set_entry_point("classifier")
# 条件分岐
conditional_workflow.add_conditional_edges(
"classifier",
route_query,
{
"technical": "technical",
"business": "business",
"general": "general"
}
)
# 各エージェントから終了へ
conditional_workflow.add_edge("technical", END)
conditional_workflow.add_edge("business", END)
conditional_workflow.add_edge("general", END)
conditional_app = conditional_workflow.compile()
# 実行例
result = conditional_app.invoke({
"query": "Kubernetesのデプロイメント戦略について教えてください",
"query_type": "",
"result": ""
})
print(f"回答: {result['result']}")実践例: コンテンツ制作システム
複数のエージェントを連携させた実用的なコンテンツ制作システムを実装します。
from langchain.tools import tool
from langchain_community.tools.tavily_search import TavilySearchResults
# ツールの定義
@tool
def web_search(query: str) -> str:
"""Webから情報を検索"""
search = TavilySearchResults(max_results=5)
results = search.invoke(query)
return str(results)
@tool
def save_draft(content: str, filename: str) -> str:
"""下書きを保存"""
with open(f"drafts/{filename}", "w", encoding="utf-8") as f:
f.write(content)
return f"保存完了: {filename}"
class ContentCreationState(TypedDict):
topic: str
research_data: str
outline: str
draft: str
final_content: str
feedback: str
iteration: int
def research_node(state: ContentCreationState):
"""リサーチノード"""
# Webから情報を収集
search_results = web_search.invoke(state["topic"])
# LLMで情報を整理
prompt = f"""
トピック: {state['topic']}
以下の検索結果を分析し、重要なポイントをまとめてください:
{search_results}
"""
result = llm.invoke(prompt)
return {"research_data": result.content, "iteration": 0}
def outline_node(state: ContentCreationState):
"""アウトライン作成ノード"""
prompt = f"""
以下のリサーチ結果を基に、記事のアウトラインを作成してください:
トピック: {state['topic']}
リサーチ結果:
{state['research_data']}
アウトライン形式:
1. はじめに
2. 主要セクション1
3. 主要セクション2
...
"""
result = llm.invoke(prompt)
return {"outline": result.content}
def writing_node(state: ContentCreationState):
"""執筆ノード"""
prompt = f"""
以下のアウトラインに従って記事を執筆してください:
トピック: {state['topic']}
アウトライン:
{state['outline']}
リサーチ結果:
{state['research_data']}
要件:
- 2000文字以上
- 具体的な例を含める
- 読みやすい構成
"""
result = llm.invoke(prompt)
return {"draft": result.content}
def review_node(state: ContentCreationState):
"""レビューノード"""
prompt = f"""
以下の記事をレビューし、改善点をフィードバックしてください:
{state['draft']}
評価基準:
- 内容の正確性
- 構成の論理性
- 読みやすさ
- 具体例の適切性
フィードバック形式:
良い点:
- ...
改善点:
- ...
総合評価: (改善不要 / 軽微な修正 / 大幅な修正)
"""
result = llm.invoke(prompt)
feedback = result.content
# 改善が必要かどうかを判定
needs_revision = "大幅な修正" in feedback or "軽微な修正" in feedback
return {
"feedback": feedback,
"iteration": state["iteration"] + 1
}
def revision_node(state: ContentCreationState):
"""修正ノード"""
prompt = f"""
以下のフィードバックに基づいて記事を修正してください:
【元の記事】
{state['draft']}
【フィードバック】
{state['feedback']}
修正版:
"""
result = llm.invoke(prompt)
return {"draft": result.content}
def finalize_node(state: ContentCreationState):
"""最終化ノード"""
# 最終版として確定
final = state["draft"]
# ファイルに保存
save_draft.invoke({
"content": final,
"filename": f"{state['topic'].replace(' ', '_')}_final.md"
})
return {"final_content": final}
def should_revise(state: ContentCreationState):
"""修正が必要かどうかを判定"""
# 最大反復回数を超えたら終了
if state["iteration"] >= 3:
return "finalize"
# フィードバックに基づいて判定
if "改善不要" in state["feedback"]:
return "finalize"
else:
return "revise"
# コンテンツ制作ワークフローの構築
content_workflow = StateGraph(ContentCreationState)
# ノードの追加
content_workflow.add_node("research", research_node)
content_workflow.add_node("outline", outline_node)
content_workflow.add_node("writing", writing_node)
content_workflow.add_node("review", review_node)
content_workflow.add_node("revision", revision_node)
content_workflow.add_node("finalize", finalize_node)
# フローの定義
content_workflow.set_entry_point("research")
content_workflow.add_edge("research", "outline")
content_workflow.add_edge("outline", "writing")
content_workflow.add_edge("writing", "review")
# 条件分岐: レビュー後の処理
content_workflow.add_conditional_edges(
"review",
should_revise,
{
"revise": "revision",
"finalize": "finalize"
}
)
# 修正後は再度レビュー
content_workflow.add_edge("revision", "review")
content_workflow.add_edge("finalize", END)
# コンパイル
content_app = content_workflow.compile()
# 実行
result = content_app.invoke({
"topic": "AIエージェントの活用事例",
"research_data": "",
"outline": "",
"draft": "",
"final_content": "",
"feedback": "",
"iteration": 0
})
print("=== 最終記事 ===")
print(result["final_content"])エージェント間のコミュニケーション
メッセージパッシング
エージェント間で構造化されたメッセージを交換する方法です。
from pydantic import BaseModel
from typing import Literal
class Message(BaseModel):
sender: str
receiver: str
message_type: Literal["request", "response", "notification"]
content: dict
class MessageBus:
"""メッセージバスパターン"""
def __init__(self):
self.messages = []
self.subscribers = {}
def publish(self, message: Message):
"""メッセージを発行"""
self.messages.append(message)
# 購読者に通知
if message.receiver in self.subscribers:
for callback in self.subscribers[message.receiver]:
callback(message)
def subscribe(self, agent_name: str, callback):
"""エージェントがメッセージを購読"""
if agent_name not in self.subscribers:
self.subscribers[agent_name] = []
self.subscribers[agent_name].append(callback)
# 使用例
message_bus = MessageBus()
def agent_a_handler(message: Message):
print(f"Agent A received: {message.content}")
message_bus.subscribe("agent_a", agent_a_handler)
# メッセージ送信
message_bus.publish(Message(
sender="agent_b",
receiver="agent_a",
message_type="request",
content={"action": "process_data", "data": [1, 2, 3]}
))共有メモリー
エージェント間で状態を共有する方法です。
from langchain.memory import ConversationBufferMemory
class SharedMemory:
"""共有メモリー"""
def __init__(self):
self.memory = ConversationBufferMemory()
self.shared_data = {}
def set(self, key: str, value: any):
"""データを保存"""
self.shared_data[key] = value
def get(self, key: str, default=None):
"""データを取得"""
return self.shared_data.get(key, default)
def add_conversation(self, role: str, content: str):
"""会話履歴に追加"""
self.memory.chat_memory.add_message(
{"role": role, "content": content}
)
def get_conversation_history(self):
"""会話履歴を取得"""
return self.memory.load_memory_variables({})
# 使用例
shared_memory = SharedMemory()
# エージェントAがデータを保存
shared_memory.set("research_results", {"topic": "AI", "findings": ["..."]})
# エージェントBがデータを読み取り
results = shared_memory.get("research_results")パフォーマンスと最適化
並列実行の最適化
import asyncio
from typing import List
async def parallel_agent_execution(agents: List, input_data):
"""複数のエージェントを並列実行"""
tasks = [
asyncio.create_task(agent.ainvoke(input_data))
for agent in agents
]
results = await asyncio.gather(*tasks)
return results
# 使用例
async def main():
agents = [market_analyst, competitor_analyst, tech_analyst]
results = await parallel_agent_execution(
agents,
{"input": "市場分析を実行"}
)
return results
# 実行
results = asyncio.run(main())キャッシング
from functools import lru_cache
import hashlib
class CachedAgent:
def __init__(self, agent):
self.agent = agent
self.cache = {}
def invoke(self, input_data: dict):
# 入力のハッシュを計算
input_hash = hashlib.md5(
str(input_data).encode()
).hexdigest()
# キャッシュにあれば返す
if input_hash in self.cache:
print("Cache hit!")
return self.cache[input_hash]
# エージェントを実行
result = self.agent.invoke(input_data)
# キャッシュに保存
self.cache[input_hash] = result
return result実運用での成果
弊社のマルチエージェントシステム導入事例では、以下の成果を達成しました:
- コンテンツ制作時間: 従来の 1/3に短縮
- 品質スコア: 人間によるレビューで 85%が高評価
- コスト削減: API呼び出しコストを 45%削減(並列実行とキャッシングにより)
- 稼働率: 24時間365日の自動処理を実現
おわりに
LangChainとLangGraphを使ったマルチエージェントシステムは、複雑な業務プロセスの自動化を実現する強力なツールです。
本記事で紹介した設計パターンを組み合わせることで、様々なユースケースに対応できる柔軟なシステムを構築できます。
マルチエージェントシステム導入の際は、以下のポイントを押さえることをお勧めします:
- 役割の明確化: 各エージェントの責務を明確に定義
- 適切なパターン選択: タスクの特性に応じた実行パターンの選択
- エラーハンドリング: エージェント間の通信エラーへの対応
- パフォーマンス最適化: 並列実行とキャッシングの活用
- モニタリング: エージェントの動作状況を継続的に監視
弊社では、これらの知見を活かして、お客様のビジネスに最適なマルチエージェントシステムの構築を支援しています。