Google Antigravity 実践ガイド (Deep Dive) - 複雑なコンテキスト管理とメモリの最適化
Google Antigravity 実践ガイドへようこそ
この記事の要点
Q: Google Antigravityの能力を最大限に引き出すには?
Q: エージェントの記憶をどう管理すべき?
Q: ハルシネーションをどう防ぎますか?
Q: リファクタリングの成功率を高めるには?
本記事は、Zennで公開中の Google Antigravity 実践ガイドシリーズ(全3回) の続編となる、統合的な詳細・実践編(Deep Dive)です。
Zennのシリーズでは、以下の基礎テーマを扱いました:
- 日本語環境の最適化(プロンプト設定)
- ワークフローの自動化(開発サイクルの効率化)
- チームガバナンス(ルールと品質管理)
本記事では、これら基礎を踏まえた上で、実際の開発現場で直面する 「エージェントが文脈を忘れてしまう」「複雑なプロジェクト構造を理解してくれない」 といった課題に対し、Antigravityの 「メモリ機能」 と 「コンテキスト管理」 を駆使して解決する、より高度なテクニックを解説します。
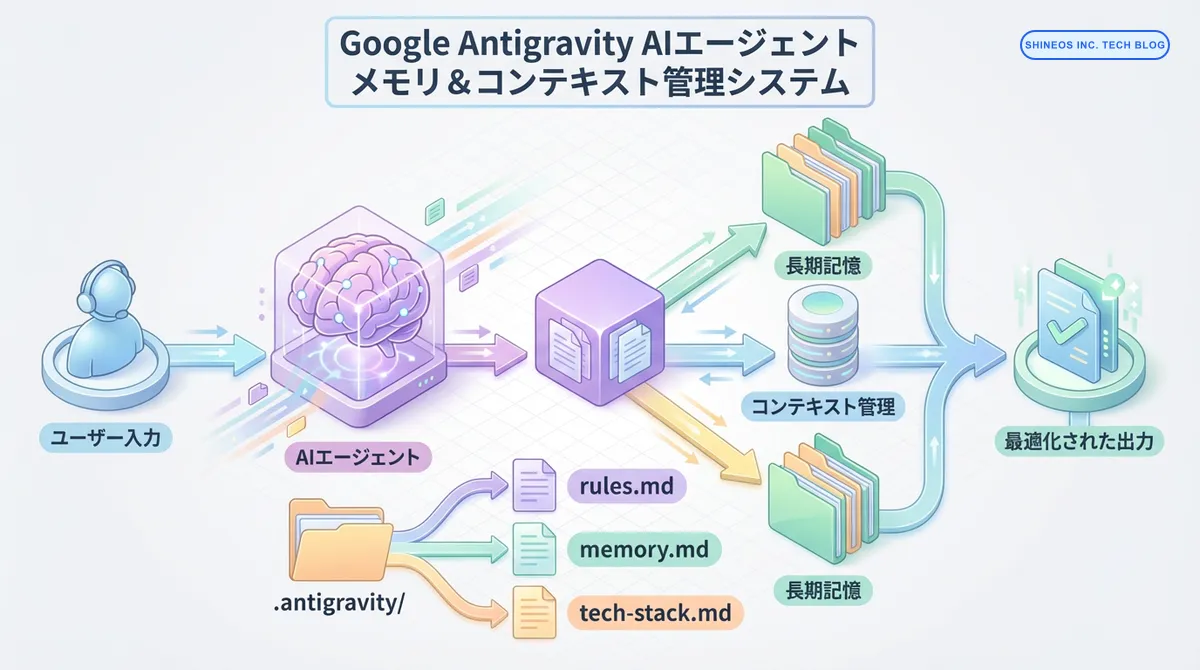
1. エージェントの「長期記憶」をハックするには?
Google Antigravityのエージェントは非常に強力ですが、デフォルトの状態では「短期記憶(そのセッション内の会話)」に頼りがちです。大規模なリポジトリや複雑な仕様を持つプロジェクトでは、エージェントがつぎはぎの知識でコードを生成し、バグを生む原因になります。
解決策は、.agent/ ディレクトリ配下のファイルを「長期記憶」として構造化することです。
プロジェクトメモリの3層構造とは?
私たちは、エージェントの記憶を以下の3層で管理することを推奨しています。
Layer 1: 絶対的なルール (rules.md)
プロジェクトに関わる全員(人間とAI)が守るべき憲法です。曖昧さを排除し、具体的に記述します。
# Coding Standards
1. **Type Safety**: `any` 型の使用は禁止。型定義が困難な場合は `unknown` を使用し、バリデーションを行うこと。
2. **Error Handling**: すべての非同期処理は `try-catch` で囲み、エラーは `AppError` クラス(`src/utils/error.ts`)を使用してラップすること。
3. **Naming**: ブール値変数は `is`, `has`, `should` で始めること(例: `isLoading`, `hasPermission`)。Layer 2: 文脈と暗黙知 (memory.md)
開発中に決定した設計判断や、「なぜそうなっているのか」という背景情報を記録します。これは動的に更新されていくべきファイルです。
# Architectural Decisions
- **Why Zustand?**: Reduxはボイラープレートが多すぎるため、軽量なZustandを採用。`src/stores/` にスライスごとに分割して配置する。
- **Authentication**: Auth0を使用しているが、プロバイダー側の都合でトークン更新ロジックに特殊なリトライ処理が入っている(`src/auth/provider.tsx` 参照)。ここを変更する際は必ずSREチームの確認が必要。Layer 3: 技術スタックの固定 (tech-stack.md)
エージェントに「推測」させないための重要な定義ファイルです。
# Tech Stack Definition
- **Framework**: Next.js v14.1.0 (App Router Only - Pages Router is forbidden)
- **UI Library**: Tailwind CSS v3.4
- **State Management**: Zustand v4.5
- **Data Fetching**: TanStack Query v5 (Strictly use `useSuspenseQuery` for data fetching)
- **Testing**: Vitest + React Testing LibraryPoint:
特に 「使ってはいけない機能(Negative Constraints)」 を明記するのが効果的です。例:「Pages Routerは禁止」「useEffect でのデータフェッチは禁止」など。
2. コンテキストウィンドウの「断捨離」術とは?
最新のLLMはコンテキストウィンドウ(扱える情報量)が広がっていますが、「ゴミを入れればゴミが出てくる(Garbage In, Garbage Out)」 の原則は変わりません。無関係なファイルを大量に読み込ませることは、エージェントの思考を鈍らせ、ハルシネーション(幻覚)の原因になります。
.agentignore によるノイズ除去の効果とは?
.gitignore とは別に、「人間には必要だがエージェントには読ませたくないファイル」 を定義します。
# .agentignore
# ビルド成果物は文脈のノイズになる
dist/
.next/
build/
# 巨大なロックファイルはトークンを浪費するだけ
package-lock.json
yarn.lock
# テストデータやモック
mock_data_large/
*.csv
*.jsonl
# 生成された型定義(ソースの型定義があれば十分)
src/generated/graphql.ts@codebase 使用時の落とし穴とは?
注意:
@codebase コマンドでリポジトリ全体を検索させるのは便利ですが、検索精度に依存するため、エージェントが「見当違いのファイル」を参照する可能性があります。
プロフェッショナルなアプローチ:
- まずファイルツリーを確認する(
@treeやls)。 - 関連しそうなファイルだけをピンポイントで指定する(
@files src/foo.ts src/bar.ts)。 - 本当に必要な部分だけを読み込ませて、エージェントの「脳」をクリアに保つ。
失敗談:
以前、モノレポ構成のプロジェクトで @codebase を使ってリファクタリングを指示したところ、エージェントが mobile/ ディレクトリ(React Native)のコードを web/ ディレクトリ(Next.js)に混入させてしまい、ビルドエラーの解消に半日を費やしました。
それ以来、** .agentignore で互いのディレクトリを隠蔽** し、必要な時だけピンポイントで参照させる運用に変えたところ、ハルシネーションはほぼゼロになりました。
3. 実践シナリオ:複雑なリファクタリングを成功させるには?
具体的なシナリオで、メモリとコンテキスト管理の効果を見てみましょう。
状況:
レガシーな fetch ベースのデータ取得処理を、TanStack Query に移行したい。しかし、エラーハンドリングのロジックが複雑で壊したくない。
悪いプロンプト例(文脈なし)
src/api/user.tsを TanStack Query に書き換えて。
これだと、プロジェクト独自のエラーハンドリングや型定義が無視され、一般的な(動かない)コードが生成される可能性が高いです。
良いプロンプト例(コンテキスト制御)
システムコンテキスト: tech-stack.md, rules.md
ユーザー:
src/api/user.ts の `getUser` 関数を TanStack Query の `useSuspenseQuery` を使う形にリファクタリングしてください。
条件:
1. `rules.md` のエラーハンドリング規定に従い、`AppError` でラップすること。
2. `memory.md` にある通り、Auth0のトークンリフレッシュロジックは維持すること。
3. 既存の型定義 `UserResponse` を再利用すること。
参照ファイル: @files src/api/user.ts src/utils/error.ts src/auth/token.tsこのように、「参照すべきルール」 と 「守るべき制約」 を明示し、必要なファイルだけを渡すことで、一発で動作するコードが生成される確率が劇的に向上します。
4. エージェントが嘘をつくときの対処法とは?
エージェントが「存在しない関数を使おうとする」または「修正したはずのコードが直っていない」場合、以下の手順でデバッグを行います。
1. 「何が見えているか」を問う
エージェントさん、今あなたのコンテキストにはどのファイルが読み込まれていますか?
rules.mdの内容は把握していますか?
2. コンテキストをリセットする
長時間のセッションで会話履歴が溜まると、古い指示がノイズになります。思い切ってセッションをリセット(/clear や New Chat)し、クリーンな状態で再開するのが近道です。
3. Step-by-Step思考を強制する
コードを書く前に、修正計画を箇条書きで出力してください。その際、変更が影響するファイル一覧も挙げてください。
これにより、エージェント自身の「思考の整理」を促し、論理的な誤りを防ぐことができます。
おすすめのカスタムコマンド設定例
よく使うコンテキストセットを .agent/params.json (または設定ファイル) にショートカット化しておくと便利です。
{
"commands": [
{
"name": "Design Review",
"description": "設計と実装の整合性をチェック",
"prompt": "現在開いているファイルの実装が、`docs/architecture.md` の設計指針と `rules.md` のコーディング規約に合致しているかレビューし、違反箇所を指摘してください。",
"context": ["docs/architecture.md", "rules.md", "@active-file"]
},
{
"name": "Generate Test",
"description": "Vitest用テストの生成",
"prompt": "`tech-stack.md` のテストスタックに基づき、選択したコードの単体テストを作成してください。境界値テストとエラー系テストを網羅すること。",
"context": ["tech-stack.md", "@active-selection"]
}
]
}よくある質問
Q: .agent/ ディレクトリはGit管理すべきですか?
A: はい、チームで共有するためにGit管理すべきです。
ただし、個人固有の設定(APIキーなど)は含めないでください。Shineosでは .agent/.env のようなファイルは .gitignore に追加する運用としています。
Q: すでにある .cursorrules と競合しませんか?
A: 基本的に競合しませんが、役割を分けることを推奨します。
Antigravity(.agent/)は「長期記憶・プロジェクトの文脈」として扱い、CursorRulesは「エディタの挙動・当面のタスク制御」として使い分けるのが最も効率的です。
Q: エージェントが memory.md を勝手に書き換えて混乱しませんか?
A: エージェントの書き込み権限を制限するか、プルリクエスト経由でのみ更新を受け入れる運用ルールを rules.md に記載することで制御できます。
私たちは、「重要な設計変更は人間がレビューしてマージする」というルールを徹底しています。
筆者の視点:なぜAntigravityなのか?
導入の動機
Github Copilotだけでは、「プロジェクト全体の文脈」を理解した提案ができず、結局人間が修正する手間が発生していたため、メモリ機能を持つAntigravityの導入を決めました。
実践での苦労
正直、最初のセットアップ(.agent/ ディレクトリの整備)には骨が折れました。「何を記憶させて、何を忘れさせるか」のチューニングに1週間ほど試行錯誤が必要でした。
発見と本音
体感速度の比較: コンテキストを最適化したAntigravityは、最適化していない状態に比べて、コード生成の精度が「体感値で3倍」違います。 以前は3回やり直していた指示が、1回で意図通りのコードになって返ってくるようになり、レビュー時間が大幅に短縮されました。これはスペック表には現れない、現場ならではのメリットです。
推奨する人・しない人
- おすすめ: 大規模な既存コードベースを持つチーム、独自の設計ルールを厳守したいプロジェクト。
- 非推奨: “とりあえず動くコード”を書き捨てたいだけの個人開発(セットアップの手間がペイしない)。
まとめ:AIを「ジュニアエンジニア」から「テックリード」へ
Google Antigravityを使いこなす鍵は、「どれだけ良質な情報を与え、どれだけノイズを遮断するか」 にあります。
- 長期記憶(
.agent/) を整備し、プロジェクトの「常識」を教え込む。 - 無視リスト(
.agentignore) で、エージェントの集中力を守る。 - プロンプト で、文脈を正確に指定し、思考を誘導する。
これらを実践することで、AIエージェントは単なる「コード生成機」から、あなたの意図を汲み取り、先回りして提案してくれる 「頼れるパートナー」 へと進化します。
🚀 さらに詳しく学ぶ(基礎編シリーズ)
まだ基礎設定に不安がある方は、以下のZenn記事シリーズも併せてご覧ください。
1. 日本語環境の最適化
2. ワークフローの自動化
3. チームガバナンス
おわりに
私たちShineosでは、このようなAIエージェントを活用した開発プロセスの最適化支援や、SaaSプロダクト開発支援を行っています。 「AIツールを入れたけれど使いこなせていない」「開発効率が頭打ちになっている」といったお悩みがあれば、ぜひお気軽にご相談ください。
おわりに
私見(Shineos Dev Team)
個人的には、Google Antigravityは「魔法の杖」ではありませんが、「優秀な秘書」に育てる楽しさ があります。
最初は全くルールを守らなかったエージェントが、rules.md を更新するたびに賢くなり、最終的には「ここは規定のアーキテクチャに違反していますよ」と、人間側を指摘してくるようになった時は感動しました。
まだ導入ハードルは少し高いですが、試してみる価値は十分にあります。あなたのチームだけの「最強のエージェント」を育ててみてください。