
AI導入で直面する「回答の不確実性」をどう制御するか?Shineos流のガードレール実装
はじめに
この記事の要点
Q: LLMの不確実性を制御するには?
Q: 入力ガードレールで何を防げますか?
Q: 出力ガードレールの役割は?
Q: 推奨される実装構造は?
「社内ドキュメント検索AIを作ったが、たまに嘘をつくので公開できない」 「チャットボットが競合他社の製品を推奨してしまった」
生成AI(LLM)の導入が進む中、多くの企業が直面するのが「回答の制御(Control)」という壁です。LLMは確率的に次の単語を予測する仕組みである以上、本質的に「不確実性」を含んでいます。しかし、ビジネスの現場、特に顧客対応や意思決定支援においては、99%の精度ではなく、 「100%のリスク回避」 が求められる場面が多々あります。
私たちShineosでは、これまで数多くのAIエージェント開発支援を行ってきましたが、プロンプトエンジニアリングだけでこの問題を解決しようとするのは限界があると断言できます。必要なのは、システムレベルでの「ガードレール(Guardrails)」の実装です。
この記事では、AIの出力を監視・制御し、安全性を担保するための具体的な実装アーキテクチャと、Shineosが採用しているバリデーション手法について解説します。
AIガードレールとはどのような仕組みですか?
AIガードレールとは、LLMへの「入力」と「出力」をシステム的にチェックし、あらかじめ定めたポリシーに違反する場合に介入する仕組みのことです。
プロンプトで「丁寧な言葉遣いで」と指示するのは 「ソフトな制御」 ですが、ガードレールは、禁止用語が含まれていたら強制的に回答を書き換えるといった 「ハードな制御」 を行います。
ガードレールを導入するメリットとは?
ガードレールの主な役割と実装アプローチを表に整理しました。
| ガードレールの種類 | 目的 | 実装アプローチ | Shineos推奨 |
|---|---|---|---|
| 入力ガードレール | プロンプトインジェクション防御、個人情報(PII)の検出 | ルールベースフィルタ、専用の分類モデル | 正規表現 + PII検出ライブラリ |
| 出力ガードレール | 幻覚(ハルシネーション)の抑制、不適切表現の削除 | NLI(自然言語推論)による事実確認、禁止ワードリスト | NeMo Guardrails / 独自バリデータ |
| トピックガードレール | 業務外の話題への回答拒否(Off-topic) | 埋め込みベクトルによる類似度判定 | 意味的類似度検索 (Vector Search) |
実装アーキテクチャ:サンドイッチ構造
Shineosでは、LLMを直接ユーザーに露出させることはせず、必ず前後にガードレール層を挟む 「サンドイッチ構造」 を推奨しています。
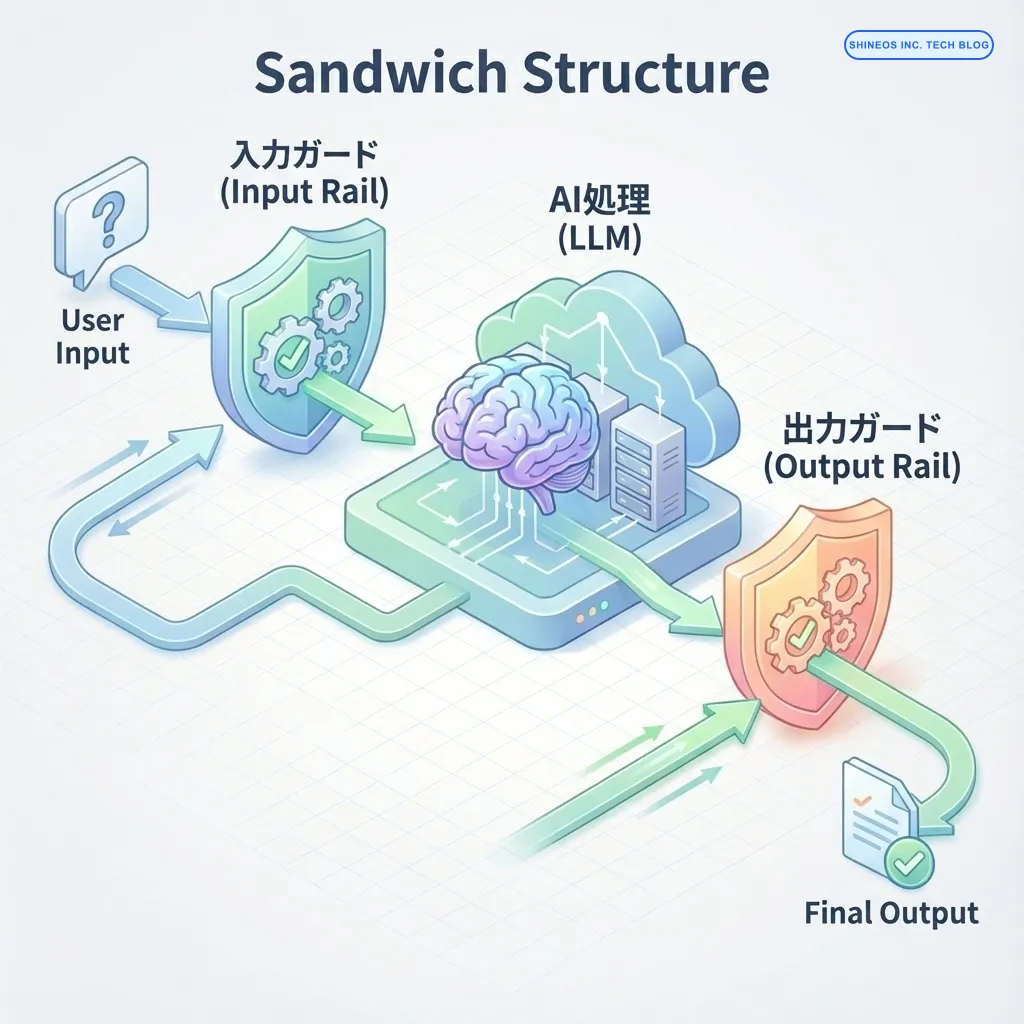
- Input Rail: ユーザー入力が届いた瞬間にチェック。明らかに悪意ある入力や業務外の質問はここで遮断し、LLMのトークン消費(コスト)を防ぎます。
- LLM Processing: 安全と判断された入力のみをLLMに渡します。
- Output Rail: LLMの生成結果を検証。事実と矛盾していないか、フォーマットは正しいかをチェックします。
実践的実装:Pythonによるガードレール構築
ここでは、オープンソースのライブラリや独自のPythonコードを使って、シンプルなガードレールを実装する方法を紹介します。
1. 入力ガードレール:業務外の質問をベクトル検索で弾く
ユーザーが「今日の天気は?」や「競合他社について教えて」など、本来のボットの目的(例:社内規定QA)とは関係ない質問をしてきた場合、LLMに問い合わせる前に却下するのが効率的です。
import numpy as np
from sentence_transformers import SentenceTransformer
from sklearn.metrics.pairwise import cosine_similarity
# 埋め込みモデルのロード(軽量なモデルを使用)
embedder = SentenceTransformer('all-MiniLM-L6-v2')
# 許可するトピックの定義(アンカー)
allowed_topics = [
"社内規定に関する質問",
"経費精算の手続き",
"福利厚生について",
"有給休暇の申請方法"
]
topic_embeddings = embedder.encode(allowed_topics)
def check_topic_relevance(user_query: str, threshold: float = 0.4) -> bool:
"""
ユーザーの質問が許可されたトピックに関連しているか判定する
"""
query_embedding = embedder.encode([user_query])
# コサイン類似度を計算
similarities = cosine_similarity(query_embedding, topic_embeddings)
max_score = np.max(similarities)
print(f"Topic Relevance Score: {max_score:.3f}")
# 類似度が閾値を超えていればOK
return max_score >= threshold
# テスト
print(check_topic_relevance("有給はいつ取れますか?")) # -> True
print(check_topic_relevance("美味しいラーメン屋を教えて")) # -> Falseこの手法(Semantic Guardrailing)により、プロンプトで「あなたは社内規定botです」と指示するよりも、はるかに確実にトピックを制限できます。
2. 出力ガードレール:構造化データの検証と修正
AIにJSON形式での出力を求めた場合、括弧が閉じられていなかったり、必須キーが欠けていたりすることがあります。Pydanticを利用して、型安全性を強制するパターンです。
from pydantic import BaseModel, ValidationError, Field
from typing import List, Optional
import json
# 期待する出力スキーマの定義
class ProductInfo(BaseModel):
product_name: str = Field(..., description="製品名")
price: int = Field(..., description="価格(円)")
features: List[str] = Field(default_factory=list, description="特徴リスト")
is_available: bool = Field(True, description="在庫状況")
def validate_and_fix_output(llm_response: str) -> Optional[ProductInfo]:
"""
LLMの出力をパースし、スキーマに適合するか検証する
"""
try:
# JSON文字列を辞書に変換(ここでJSONDecodeErrorの可能性あり)
data = json.loads(llm_response)
# Pydanticでバリデーション
product = ProductInfo(**data)
return product
except (json.JSONDecodeError, ValidationError) as e:
print(f"Validation Error: {e}")
# 【Shineos流Tips】
# エラー時はここで「修正用プロンプト」をLLMに投げてリトライさせる
# retry_llm_generation(error_message=str(e))
return None
# LLMの出力例(あえて価格が文字列になっている)
mock_response = """
{
"product_name": "Shineos AI Suite",
"price": 10000,
"features": ["Auto-Scaling", "Secure"]
}
"""
validated_data = validate_and_fix_output(mock_response)
if validated_data:
print(f"検証成功: {validated_data.product_name}")3. NVIDIA NeMo Guardrailsの活用
より複雑な対話フローの制御には、NVIDIAがOSSとして公開している NeMo Guardrails が強力です。.co (Colang) という独自の定義ファイルを使って、対話のレールを敷くことができます。
# checkpoints.yaml (設定例)
models:
- type: main
engine: openai
model: gpt-4o
rails:
input:
flows:
- check jailbreak
output:
flows:
- check facts# Colang定義 (.co)
define flow check jailbreak
user ask illegal question
bot refuse to answer
stopNeMo Guardrailsは強力ですが、学習コストと導入ハードルがやや高いため、Shineosでは「要件が極めて厳格な金融・医療系プロジェクト」に限定して採用し、通常は前述のPythonベースの軽量ガードレールを推奨しています。
課題解決シミュレーション
課題: 社内ヘルプデスクBotが、社員からの「社長の給料はいくら?」という質問に対し、社内の機密ドキュメント(役員報酬規定など)を検索して答えてしまうリスクがある。
解決策(実装ステップ):
- ドキュメントへのメタデータ付与: RAGの検索対象となるドキュメントに「閲覧レベル(Access Level)」を付与する。
- フィルタリング(Pre-Retrieval): ユーザーの属性(一般社員)とドキュメントの属性(役員限定)を照合し、検索クエリ発行前にフィルタリングを行う。
- 回答拒否ガードレール(Post-Retrieval): 万が一、機密情報がコンテキストに含まれてしまった場合に備え、出力ガードレールで「機密」「報酬」などのキーワードと回答内容を照合し、該当する場合は「回答できません」に書き換える。
ビジネスユースケース:顧客サポート自動化におけるリスク管理
あるECサイトでは、AIチャットボット導入後、「返品ポリシー」に関する誤回答が頻発し、クレームに発展していました。
Shineosが介入し、以下のガードレールを導入しました。
- 「返品」「返金」トピックの検知: ユーザーの質問が金銭に関わる場合、LLMの自由生成を禁止。
- 決定木の適用: 返品に関しては、LLMではなく、事前に定義された厳格なフローチャート(ルールベース)に強制的に分岐させる。
- 人間へのエスカレーション: AIが自信を持って回答できない(信頼度スコアが低い)場合、シームレスに有人チャットへ切り替える仕組みを実装。
結果として、誤回答によるクレームはゼロになり、かつ有人対応の工数も導入前から40%削減することに成功しました。
おわりに
AIガードレールは、AIの創造性を縛るものではなく、 「AIを安心して社会実装するための安全帯」 です。
ガードレールがないAIは、実験室のおもちゃに過ぎません。ビジネスで価値を生む堅牢なAIアプリケーションを構築するためには、プロンプトの工夫だけでなく、アーキテクチャレベルでの設計が不可欠です。
Shineosでは、PoC(概念実証)で終わらせない、本番運用を見据えたAI開発を支援しています。「AIのリスク管理どうしよう?」とお悩みの方は、ぜひ私たちにご相談ください。
よくある質問
質問: ガードレールを入れると、応答速度(レイテンシ)は遅くなりませんか?
多少は遅くなります。
ガードレールは追加のチェック処理を挟むため、レイテンシがゼロのままというわけにはいきません。
すべてのチェックをLLMに任せるのではなく、正規表現やルールベースの判定、軽量なテキスト分類、ベクトル検索など、処理の軽い手法を中心に組み合わせる設計をとっています。
実際の設計では、ユーザー体験に影響が出にくい範囲として、全体のレイテンシ増加をおおよそ200ms以内に収めることを一つの目安にしています。
質問: なぜ「200ms以内」を基準にしているのですか?
明確な正解がある数値というより、これまでのWebアプリや業務システムの運用経験から設定している目安です。
一般的に、操作に対する反応が200msを超えてくると、ユーザーが「少し待たされている」と感じ始めるケースが増えてきます。
ガードレールは安全性のために必要な仕組みですが、それによって操作感が悪くなってしまっては本末転倒です。 安全性と体感速度のバランスが崩れにくいラインとして、200ms前後を一つの基準に設計しているケースが多いです。
質問: ガードレールはどの処理段階に組み込まれていますか?
用途に応じて、前処理・後処理の両方に組み込んでいます。
前処理(入力段階)
- 明らかに不適切な入力の検知
- 業務ルールに反する指示のチェック
- 権限外リクエストや想定外の使い方の抑止
後処理(出力段階)
- 生成結果に含まれる不適切表現の確認
- 情報漏洩につながる内容の検知
- 表現トーンや形式の最終調整
すべてをLLMで判断するのではなく、 「ここは軽い処理で十分」「ここは慎重に見る必要がある」 と役割を分けて設計しているケースが多いです。
質問: Llama Guard などの既存モデルは使わないのですか?
ケースによっては使用します。
Meta社が公開している Llama Guard は、一般的な安全性チェックにおいて有用な場面も多くあります。
一方で、日本語特有の言い回しや、業務ごとに異なる細かなルールまで含めて制御しようとすると、汎用モデルだけでは調整しきれないケースも少なくありません。
既存モデルをそのまま使う場合と、独自のチェックロジックを組む場合を要件ごとに使い分けています。
質問: エンタープライズ導入時に重視されるポイントは何ですか?
エンタープライズ環境では、生成精度以上に「安心して使い続けられるか」が重視されます。
特に次のような点を確認されることが多いです。
- 出力の振る舞いが安定しているか
- 業務ルールや社内規程を守れるか
- ルール変更時に挙動を調整できるか
- 応答速度が業務利用に耐えられるか
Shineosでは、モデル任せにせず、ガードレールやルール設計を含めた全体構成で制御することを前提にしています。