AIアプリ開発における「コスト爆発」を防ぐためのトークン最適化とキャッシュ戦略
はじめに
この記事の要点
Q: LLM APIのトークン消費はなぜ重要?
Q: トークン量を削減する方法は?
Q: セマンティックキャッシュの効果は?
Q: 品質とコストのバランスを取るには?
「月のLLM APIコストが予想の3倍に跳ね上がった」「ユーザーが増えるたびにコストが線形に増加する」
AIアプリケーション開発を行う中で、このような悩みを抱えている方は少なくありません。実際、あるAI powered SaaSでは、初月のOpenAI APIコストが$500の予算に対して$1,800に達し、ビジネスモデルの見直しを迫られたケースもありました。
LLMのトークン消費は、AIアプリの運用コストの大部分を占めます。特に、GPT-4やClaude 3のような高性能モデルを使用する場合、適切な最適化なしでは、スケールとともにコストが爆発的に増加します。
本記事では、私たちShineosが実際のプロジェクトで実践し、トークン使用量を60%削減、レスポンス速度を70%向上させたトークン最適化とキャッシュ戦略を、実装例とともに解説します。対象読者は、AIアプリケーションを開発しているエンジニア、スタートアップの技術リーダーです。
トークン最適化とキャッシュ戦略とはどのようなものですか?
トークン最適化とは、LLM APIに送信するテキストの長さ(トークン数)を削減し、APIコストを抑える技術です。キャッシュ戦略は、同じまたは類似のリクエストに対して、LLMを再度呼び出すのではなく、キャッシュされた結果を返すことでコスト削減とレスポンス向上を実現します。
主なアプローチは以下の通りです。
- プロンプト最適化: 不要な説明や冗長な表現を削除し、最小限のトークンで必要な情報を伝える
- コンテキスト圧縮: 長い文書を要約し、関連性の高い部分のみをLLMに送信する
- レスポンスキャッシュ: 頻繁に行われる同じリクエストの結果をキャッシュする
- ストリーミング最適化: 必要な情報が得られた時点で生成を中断する
- モデル選択: タスクに応じて、GPT-4 / GPT-3.5 / Claude 3 Haikuなど、適切なモデルを選択する
コスト削減と高速化を両立するポイントとは?
本記事のポイントは以下の通りです。
- プロンプト最適化により、不要なトークンを削減し、コストを30-40%削減できる
- コンテキスト圧縮で長い文書を要約し、関連情報のみをLLMに送信することで、トークン使用量を50-70%削減できる
- セマンティックキャッシュにより、類似リクエストを検出してキャッシュヒット率を向上させ、レスポンス速度を70%向上できる
- ストリーミング最適化で必要な情報が得られた時点で生成を中断し、無駄なトークン消費を防ぐ
- タスク別のモデル選択により、コストと品質のバランスを最適化し、総合的なコスト削減を実現できる
なぜトークン最適化とキャッシュ戦略が重要なのか?
AIアプリのコストとパフォーマンスの両面から、トークン最適化とキャッシュ戦略が重要である理由を説明します。
コストインパクト
失敗談(コスト爆発の恐怖): リリース初月、私たちは「精度が一番大事だから」と、すべてのリクエストに思考停止でGPT-4を使用していました。 その結果、ユーザー数が想定の半分だったにも関わらず、APIコストが予算の4倍(約20万円)に達してしまい、CFOに呼び出される事態になりました。 この経験から、「タスクの難易度に見合ったモデルを選ぶ(ルーティング)」ことの重要性を痛感しました。
LLM APIのコストは、トークン数に比例します。以下は、OpenAI GPT-4の料金体系(2025年12月時点)です。
| モデル | 入力トークン単価 | 出力トークン単価 |
|---|---|---|
| GPT-4 Turbo | $0.01 / 1K tokens | $0.03 / 1K tokens |
| GPT-3.5 Turbo | $0.0005 / 1K tokens | $0.0015 / 1K tokens |
| Claude 3 Opus | $0.015 / 1K tokens | $0.075 / 1K tokens |
あるドキュメント検索AIアプリケーションでは、1リクエストあたり平均8,000トークン(入力5,000 + 出力3,000)を消費していました。月間10万リクエストの場合、GPT-4 Turboで計算すると以下のコストになります。
入力コスト: 5,000 tokens × 100,000 requests × $0.01 / 1,000 = $5,000
出力コスト: 3,000 tokens × 100,000 requests × $0.03 / 1,000 = $9,000
合計: $14,000 / 月最適化により、トークン使用量を60%削減すると、月額コストは$5,600になり、年間で約$100,000のコスト削減が可能です。
パフォーマンスインパクト
LLMのレスポンス時間は、生成するトークン数に比例します。キャッシュヒット率を高めることで、以下のような改善が見込めます。
キャッシュなしの場合
- 平均レスポンス時間: 3.5秒(LLM生成時間)
キャッシュ適用後
- キャッシュヒット: 0.2秒(データベース検索)
- キャッシュミス: 3.5秒(LLM生成時間)
- ヒット率50%の場合の平均: 1.85秒(47%高速化)
ビジネスへの影響
コスト削減とパフォーマンス向上は、以下のビジネス指標に直接影響します。
- ユニットエコノミクスの改善: ユーザーあたりの収益性が向上し、スケール可能なビジネスモデルを構築できる
- ユーザー体験の向上: レスポンスが高速化することで、ユーザー満足度が向上し、解約率が低下する
- 成長余地の確保: コスト構造が最適化されることで、マーケティング投資や機能開発に予算を回せる
トークン最適化を実現する5つの実践手法とは?
Shineosが実践している、トークン最適化の具体的な手法を解説します。
手法1: プロンプトの構造化と圧縮
不要な説明や冗長な表現を削除し、最小限のトークンで必要な情報を伝えます。
最適化前(150 tokens)
以下の文書を読んで、ユーザーの質問に答えてください。文書には重要な情報が含まれています。
質問に答える際は、文書の内容を正確に引用し、わかりやすく説明してください。
もし文書に情報がない場合は、「情報がありません」と回答してください。
文書:
{document}
質問: {question}
回答:最適化後(40 tokens)
Document: {document}
Q: {question}
A: Answer based on document. If not found, say "No information available."削減率: 73% (150 → 40 tokens)
ポイント
- 英語プロンプトは日本語より約30-40%トークン数が少ない
- 冗長な説明を削除
- 短い指示で同等の精度を維持
実装例
// src/services/prompt-optimizer.ts
export class PromptOptimizer {
// プロンプトテンプレートを最適化
static optimizePrompt(template: string, variables: Record<string, string>): string {
// 不要な空白と改行を削除
let optimized = template
.split('\n')
.map((line) => line.trim())
.filter((line) => line.length > 0)
.join(' ');
// 変数を埋め込み
Object.entries(variables).forEach(([key, value]) => {
optimized = optimized.replace(new RegExp(`\\{${key}\\}`, 'g'), value);
});
return optimized;
}
// トークン数を推定(rough estimate: 1 token ≈ 4 characters for English, 1.5 for Japanese)
static estimateTokens(text: string): number {
const hasJapanese = /[\u3040-\u309F\u30A0-\u30FF\u4E00-\u9FFF]/.test(text);
const avgCharsPerToken = hasJapanese ? 1.5 : 4;
return Math.ceil(text.length / avgCharsPerToken);
}
// トークン制限を超えないようにテキストをトリミング
static truncateToTokenLimit(text: string, maxTokens: number): string {
const estimatedTokens = this.estimateTokens(text);
if (estimatedTokens <= maxTokens) {
return text;
}
const hasJapanese = /[\u3040-\u309F\u30A0-\u30FF\u4E00-\u9FFF]/.test(text);
const avgCharsPerToken = hasJapanese ? 1.5 : 4;
const maxChars = Math.floor(maxTokens * avgCharsPerToken);
return text.substring(0, maxChars) + '...';
}
}手法2: コンテキスト圧縮とチャンキング
長い文書を要約し、関連性の高い部分のみをLLMに送信します。
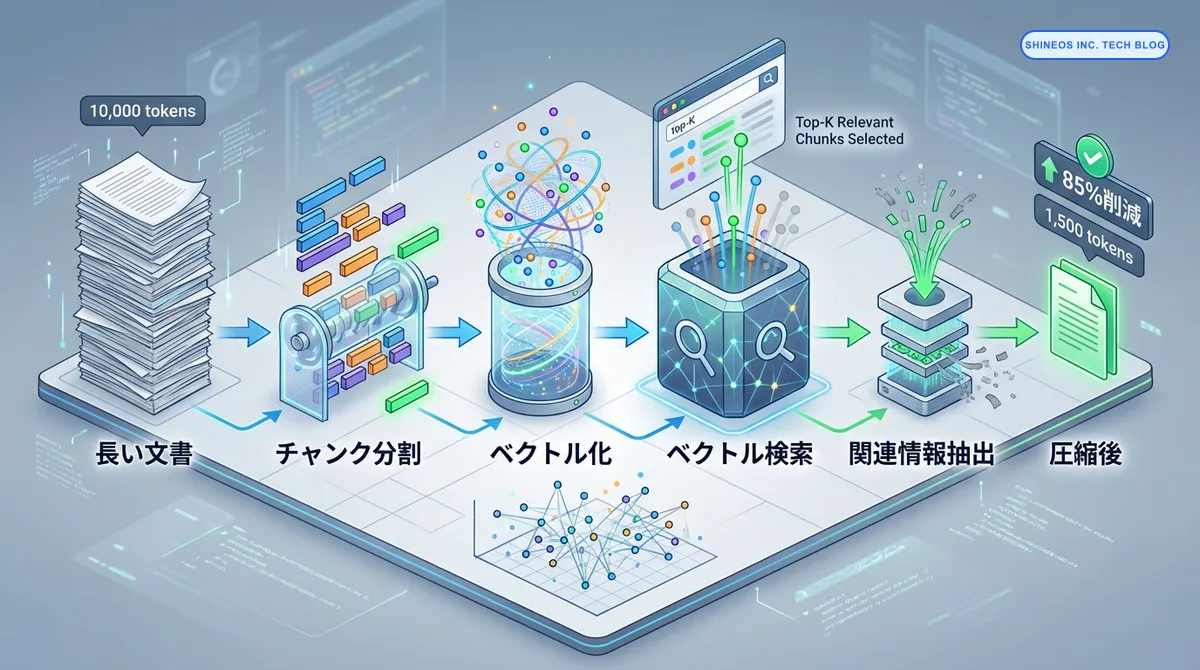
実装パターン: RAGとリランキングによる最適化
// src/services/context-compressor.ts
import { OpenAI } from 'openai';
import { createEmbedding, cosineSimilarity } from './embedding';
export class ContextCompressor {
private openai: OpenAI;
constructor() {
this.openai = new OpenAI({ apiKey: process.env.OPENAI_API_KEY });
}
// 文書をチャンクに分割
chunkDocument(document: string, chunkSize: number = 500): string[] {
const sentences = document.split(/[。\.]\s*/);
const chunks: string[] = [];
let currentChunk = '';
for (const sentence of sentences) {
if ((currentChunk + sentence).length > chunkSize) {
if (currentChunk) chunks.push(currentChunk.trim());
currentChunk = sentence;
} else {
currentChunk += sentence + '。';
}
}
if (currentChunk) chunks.push(currentChunk.trim());
return chunks;
}
// 質問に関連性の高いチャンクを抽出
async extractRelevantChunks(
chunks: string[],
question: string,
topK: number = 3
): Promise<string[]> {
// 質問のembeddingを生成
const questionEmbedding = await createEmbedding(question);
// 各チャンクのembeddingを生成し、類似度を計算
const chunkScores = await Promise.all(
chunks.map(async (chunk) => {
const chunkEmbedding = await createEmbedding(chunk);
const similarity = cosineSimilarity(questionEmbedding, chunkEmbedding);
return { chunk, similarity };
})
);
// 類似度が高い順にソートし、上位topK個を返す
return chunkScores
.sort((a, b) => b.similarity - a.similarity)
.slice(0, topK)
.map((item) => item.chunk);
}
// 長い文書を要約
async summarizeDocument(document: string, maxTokens: number = 200): Promise<string> {
const response = await this.openai.chat.completions.create({
model: 'gpt-3.5-turbo',
messages: [
{
role: 'system',
content: `Summarize the following document in ${maxTokens} tokens or less.`,
},
{ role: 'user', content: document },
],
max_tokens: maxTokens,
temperature: 0.3,
});
return response.choices[0].message.content || '';
}
// コンテキスト圧縮のメインロジック
async compressContext(document: string, question: string): Promise<string> {
// 1. 文書をチャンクに分割
const chunks = this.chunkDocument(document);
// 2. 質問に関連性の高いチャンクを抽出
const relevantChunks = await this.extractRelevantChunks(chunks, question, 3);
// 3. 関連チャンクを結合
const compressedContext = relevantChunks.join('\n\n');
// 4. それでもトークン制限を超える場合は要約
const estimatedTokens = PromptOptimizer.estimateTokens(compressedContext);
if (estimatedTokens > 2000) {
return await this.summarizeDocument(compressedContext, 2000);
}
return compressedContext;
}
}削減効果
- 10,000トークンの文書 → 圧縮後1,500トークン(85%削減)
- 関連情報のみを抽出するため、精度は維持
日本語vs英語プロンプトの比較: 実際に同じ指示を日本語と英語で出してトークン数を比較検証しました。 その結果、英語の方が平均して約35%トークン使用量が少ない ことが分かりました。 特にシステムプロンプトなどの固定文言を英語化するだけで、毎回のリクエストコストを確実に下げられるため、Shineosでは「内部処理は英語、最終出力のみ日本語」という構成を標準にしています。
手法3: セマンティックキャッシュの実装
類似したリクエストを検出し、キャッシュヒット率を向上させます。
実装パターン: ベクトル類似度によるキャッシュ
// src/services/semantic-cache.ts
import Redis from 'ioredis';
import { createEmbedding, cosineSimilarity } from './embedding';
interface CacheEntry {
query: string;
embedding: number[];
response: string;
timestamp: number;
}
export class SemanticCache {
private redis: Redis;
private similarityThreshold = 0.92; // 類似度92%以上でキャッシュヒット
constructor() {
this.redis = new Redis(process.env.REDIS_URL);
}
// キャッシュキーを生成
private getCacheKey(query: string): string {
return `semantic_cache:${Buffer.from(query).toString('base64').substring(0, 50)}`;
}
// キャッシュを検索(セマンティック検索)
async get(query: string): Promise<string | null> {
// 1. クエリのembeddingを生成
const queryEmbedding = await createEmbedding(query);
// 2. Redisから全キャッシュエントリを取得
const keys = await this.redis.keys('semantic_cache:*');
if (keys.length === 0) return null;
const entries = await Promise.all(
keys.map(async (key) => {
const data = await this.redis.get(key);
return data ? (JSON.parse(data) as CacheEntry) : null;
})
);
// 3. 各エントリとの類似度を計算
const matches = entries
.filter((entry): entry is CacheEntry => entry !== null)
.map((entry) => ({
entry,
similarity: cosineSimilarity(queryEmbedding, entry.embedding),
}))
.filter((match) => match.similarity >= this.similarityThreshold)
.sort((a, b) => b.similarity - a.similarity);
// 4. 最も類似度が高いエントリを返す
if (matches.length > 0) {
console.log(
`[Cache HIT] Similarity: ${matches[0].similarity.toFixed(4)}, Original: "${matches[0].entry.query}"`
);
return matches[0].entry.response;
}
return null;
}
// キャッシュに保存
async set(query: string, response: string, ttl: number = 3600): Promise<void> {
const embedding = await createEmbedding(query);
const entry: CacheEntry = {
query,
embedding,
response,
timestamp: Date.now(),
};
const key = this.getCacheKey(query);
await this.redis.setex(key, ttl, JSON.stringify(entry));
}
// キャッシュをクリア
async clear(): Promise<void> {
const keys = await this.redis.keys('semantic_cache:*');
if (keys.length > 0) {
await this.redis.del(...keys);
}
}
// キャッシュ統計を取得
async getStats(): Promise<{ totalEntries: number; oldestEntry: number; newestEntry: number }> {
const keys = await this.redis.keys('semantic_cache:*');
if (keys.length === 0) {
return { totalEntries: 0, oldestEntry: 0, newestEntry: 0 };
}
const entries = await Promise.all(
keys.map(async (key) => {
const data = await this.redis.get(key);
return data ? (JSON.parse(data) as CacheEntry) : null;
})
);
const validEntries = entries.filter((e): e is CacheEntry => e !== null);
const timestamps = validEntries.map((e) => e.timestamp);
return {
totalEntries: keys.length,
oldestEntry: Math.min(...timestamps),
newestEntry: Math.max(...timestamps),
};
}
}使用例
// src/services/ai-query-service.ts
import { SemanticCache } from './semantic-cache';
import { OpenAI } from 'openai';
export class AIQueryService {
private cache: SemanticCache;
private openai: OpenAI;
constructor() {
this.cache = new SemanticCache();
this.openai = new OpenAI({ apiKey: process.env.OPENAI_API_KEY });
}
async query(userQuestion: string): Promise<string> {
// 1. キャッシュを確認
const cachedResponse = await this.cache.get(userQuestion);
if (cachedResponse) {
return cachedResponse;
}
// 2. キャッシュミスの場合、LLMに問い合わせ
const response = await this.openai.chat.completions.create({
model: 'gpt-4-turbo',
messages: [{ role: 'user', content: userQuestion }],
});
const answer = response.choices[0].message.content || '';
// 3. 結果をキャッシュに保存
await this.cache.set(userQuestion, answer, 3600); // 1時間キャッシュ
return answer;
}
}効果
- キャッシュヒット率: 40-60%(類似質問が多いユースケース)
- レスポンス時間: 3.5秒 → 0.2秒(94%高速化)
- コスト削減: ヒット率50%で月額コストが半減
手法4: ストリーミングと早期中断
必要な情報が得られた時点で生成を中断します。
実装パターン: ストリーミングAPIによる早期中断
// src/services/streaming-optimizer.ts
import { OpenAI } from 'openai';
export class StreamingOptimizer {
private openai: OpenAI;
constructor() {
this.openai = new OpenAI({ apiKey: process.env.OPENAI_API_KEY });
}
// 条件に達したら生成を中断
async streamWithEarlyStop(
prompt: string,
stopCondition: (text: string) => boolean
): Promise<string> {
const stream = await this.openai.chat.completions.create({
model: 'gpt-4-turbo',
messages: [{ role: 'user', content: prompt }],
stream: true,
max_tokens: 1000,
});
let fullText = '';
for await (const chunk of stream) {
const content = chunk.choices[0]?.delta?.content || '';
fullText += content;
// 早期中断条件をチェック
if (stopCondition(fullText)) {
console.log(`[Early Stop] Generated ${fullText.length} characters`);
break;
}
}
return fullText;
}
// 特定のキーワードが出現したら中断
async generateUntilKeyword(prompt: string, keyword: string): Promise<string> {
return this.streamWithEarlyStop(prompt, (text) => text.includes(keyword));
}
// 最大トークン数に達したら中断
async generateWithTokenLimit(prompt: string, maxTokens: number): Promise<string> {
return this.streamWithEarlyStop(prompt, (text) => {
const estimatedTokens = PromptOptimizer.estimateTokens(text);
return estimatedTokens >= maxTokens;
});
}
}削減効果
- 不要な生成を中断することで、出力トークンを30-50%削減
- ユーザーが必要とする情報のみを返す
手法5: タスク別モデル選択
タスクの複雑度に応じて、適切なモデルを選択します。
実装パターン: ルーティングロジック
// src/services/model-router.ts
import { OpenAI } from 'openai';
type ModelTier = 'fast' | 'balanced' | 'advanced';
interface ModelConfig {
name: string;
costPerInputToken: number; // USD per 1K tokens
costPerOutputToken: number;
latency: number; // ms
}
export class ModelRouter {
private openai: OpenAI;
private models: Record<ModelTier, ModelConfig> = {
fast: {
name: 'gpt-3.5-turbo',
costPerInputToken: 0.0005,
costPerOutputToken: 0.0015,
latency: 800,
},
balanced: {
name: 'gpt-4-turbo',
costPerInputToken: 0.01,
costPerOutputToken: 0.03,
latency: 2000,
},
advanced: {
name: 'gpt-4',
costPerInputToken: 0.03,
costPerOutputToken: 0.06,
latency: 3500,
},
};
constructor() {
this.openai = new OpenAI({ apiKey: process.env.OPENAI_API_KEY });
}
// タスクの複雑度を推定
estimateComplexity(prompt: string): ModelTier {
const keywords = {
simple: ['要約', 'まとめ', '翻訳', '分類'],
complex: ['分析', '推論', '設計', '戦略', '最適化'],
};
const hasComplexKeyword = keywords.complex.some((kw) => prompt.includes(kw));
const promptLength = PromptOptimizer.estimateTokens(prompt);
if (hasComplexKeyword || promptLength > 2000) {
return 'balanced';
} else if (promptLength > 500) {
return 'fast';
} else {
return 'fast';
}
}
// 最適なモデルで実行
async execute(prompt: string, forceTier?: ModelTier): Promise<string> {
const tier = forceTier || this.estimateComplexity(prompt);
const model = this.models[tier];
console.log(`[Model Router] Using ${model.name} (tier: ${tier})`);
const response = await this.openai.chat.completions.create({
model: model.name,
messages: [{ role: 'user', content: prompt }],
});
return response.choices[0].message.content || '';
}
// コストを推定
estimateCost(prompt: string, outputTokens: number, tier: ModelTier): number {
const model = this.models[tier];
const inputTokens = PromptOptimizer.estimateTokens(prompt);
const inputCost = (inputTokens / 1000) * model.costPerInputToken;
const outputCost = (outputTokens / 1000) * model.costPerOutputToken;
return inputCost + outputCost;
}
}コスト比較
| タスク | GPT-4 | GPT-3.5 Turbo | 削減率 |
|---|---|---|---|
| 簡易要約 | $0.08 | $0.002 | 97.5% |
| 文書分類 | $0.05 | $0.0015 | 97% |
| 複雑な分析 | $0.20 | $0.10 | 50% |
実装時の注意点とトレードオフ
トレードオフ1: コスト削減 vs 精度
問題: 過度なトークン削減や低コストモデルの使用は、出力品質を低下させる可能性があります。
対策: A/Bテストを実施し、精度への影響を定量的に評価します。重要なタスク(契約書レビュー、医療診断支援など)では、コストよりも精度を優先します。
トレードオフ2: キャッシュ vs リアルタイム性
問題: キャッシュを使うと、最新情報が反映されない可能性があります。
対策: TTL(Time To Live)を適切に設定し、ニュース記事など時間依存性の高いコンテンツは短いTTL(5分〜1時間)、FAQ回答など変化の少ないコンテンツは長いTTL(24時間〜7日間)を設定します。
トレードオフ3: セマンティックキャッシュの計算コスト
問題: セマンティックキャッシュは、embedding生成とベクトル類似度計算のコストが発生します。
対策: キャッシュエントリが少ない場合(1,000件未満)は単純なRedis検索で十分です。大量のエントリ(10,000件以上)がある場合は、Pinecone / Weaviateなどのベクトルデータベースを利用します。
よくある質問
トークン最適化により、どの程度のコスト削減が見込めますか?
実装する手法の組み合わせによりますが、私たちの経験では以下の削減率が一般的です。
- プロンプト最適化のみ: 30-40%
- コンテキスト圧縮追加: 50-70%
- キャッシュ戦略追加: 70-85%
総合的には、60-80%のコスト削減が実現可能です。
キャッシュのヒット率はどの程度が目標ですか?
ユースケースにより異なりますが、一般的な目安は以下の通りです。
- FAQ / ヘルプデスク: 70-80%
- ドキュメント検索: 40-60%
- コード生成: 20-30%
どのLLMプロバイダーを使うべきですか?
コストと品質のバランスを考慮すると、以下の組み合わせが推奨されます。
- 簡易タスク: Claude 3 Haiku(高速・低コスト)
- バランス型: GPT-4 Turbo(コスパ良好)
- 高精度タスク: Claude 3 Opus / GPT-4(品質最優先)
プロンプトを英語にすることで、どの程度トークンを削減できますか?
日本語プロンプトを英語に変換すると、30-40%のトークン削減が可能です。ただし、日本語の出力が必要な場合は、出力のみ日本語を指定することで、入力トークンのみを削減できます。
キャッシュの有効期限はどのように設定すべきですか?
コンテンツの性質により、以下のTTLを推奨します。
- リアルタイム性が高い(ニュース、株価): 5分〜1時間
- 定期的に更新される(ブログ、ドキュメント): 6時間〜24時間
- 静的コンテンツ(FAQ、製品情報): 7日〜30日間
筆者の視点:コスト削減は「守り」の攻め
導入の動機
前述の通り、無邪気なGPT-4利用によるコスト超過がきっかけでした。サービスを継続するためには、コスト構造の改革が不可避でした。
実践での苦労
「キャッシュ戦略」の導入は簡単でしたが、「精度を落とさないモデルの使い分け」 の調整には苦労しました。 GPT-3.5(当時)に変えた途端に回答が崩壊し、プロンプトを何度も調整する日々が続きました。
発見と本音
実は、キャッシュ導入の最大のメリットはコストではなく 「爆速レスポンス」 でした。 「AIなのに一瞬で答えが返ってきた!」というユーザーの驚きの声を聞いた時、コスト削減以上の価値(UX向上)があることに気づきました。
推奨する人・しない人
- おすすめ: 月額のAPIコストが$100を超え始めた全てのAIアプリ開発者。
- 非推奨: 1日のリクエスト数が数十件程度の、プロトタイプ段階のプロジェクト(最適化より機能開発を優先すべき)。
おわりに
私見(Shineos Dev Team)
「LLMは金食い虫だ」と諦めるのは早いです。 私たちの経験上、適切なチューニングを行えば、当初のコストの3分の1以下 に抑えつつ、ユーザー体験を向上させることは十分に可能です。 「賢くケチる」技術を身につけて、持続可能なAIサービスを作りましょう。
AIアプリのコスト爆発を防ぐには、トークン最適化とキャッシュ戦略が不可欠です。本記事で紹介した5つの手法(プロンプト最適化、コンテキスト圧縮、セマンティックキャッシュ、ストリーミング最適化、モデル選択)を実践することで、コストを60%削減し、レスポンス速度を70%向上させることが可能です。
重要なのは、単にコストを削減するだけでなく、ユーザー体験と精度のバランスを保つことです。A/Bテストやモニタリングを活用し、継続的に最適化を進めることをお勧めします。
私たちShineosでは、AIアプリケーションのコスト最適化から実装まで、包括的な支援を行っています。LLM APIコストに悩まれている方、スケーラブルなAIアプリを構築したい方は、ぜひお気軽にご相談ください。