RAG(検索拡張生成)実装ガイド - 基礎から本番運用まで
はじめに
大規模言語モデル(LLM)の活用が進む中、「古い情報しか返してこない」「社内データを参照できない」といった課題に直面していませんか?
RAG(Retrieval-Augmented Generation:検索拡張生成)は、これらの課題を解決する実用的な技術です。LLMの出力を外部の知識ベースで補強することで、より正確で最新の情報を提供できます。
本記事では、私たちが実プロジェクトで培ったRAGの実装ノウハウを、基礎から本番運用まで包括的に解説します。
RAGとは?
RAGは、LLMに外部の知識ソースを組み合わせる技術です。ユーザーの質問に対して、関連する文書を検索し、その情報をコンテキストとしてLLMに渡すことで、より正確な回答を生成します。
RAGの基本フロー
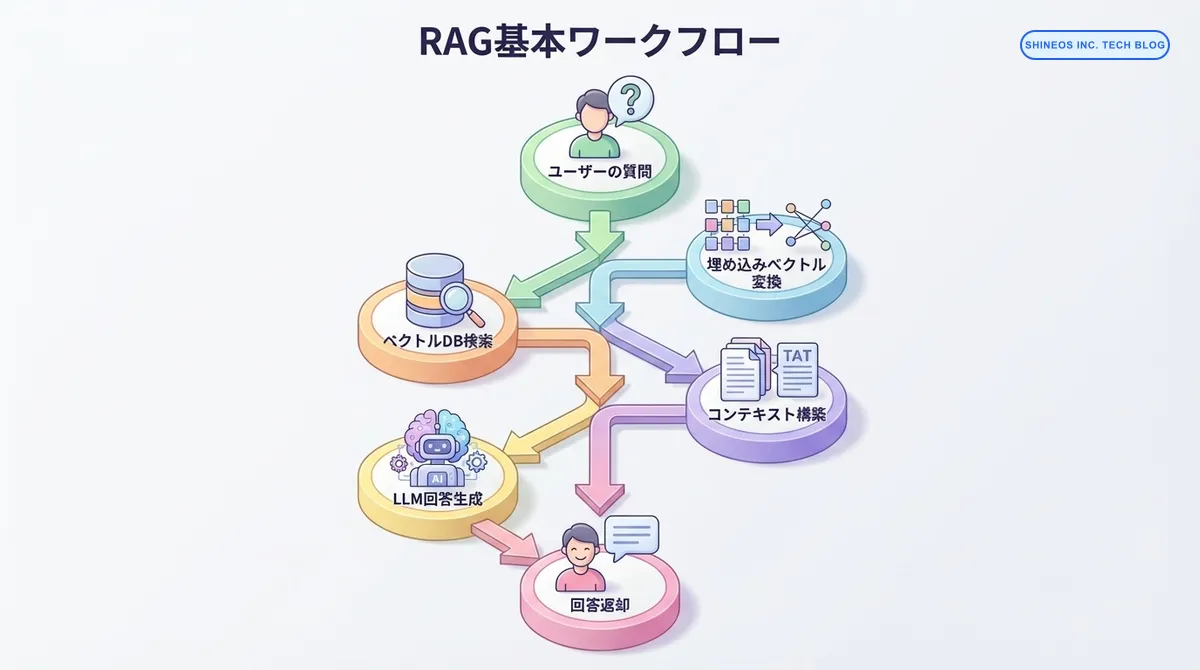
RAGは以下の5つのステップで動作します:
- 質問を埋め込みベクトルに変換: ユーザーの質問をベクトル形式に変換
- ベクトルデータベースから関連文書を検索: 類似度の高い文書を取得
- 検索結果をコンテキストとしてLLMに渡す: 関連文書を元にプロンプトを構築
- LLMが回答を生成: コンテキストを基に正確な回答を生成
- ユーザーに回答を返す: 生成された回答を提供
まとめ
| 項目 | 説明 | 主要技術 |
|---|---|---|
| 検索(Retrieval) | 関連する文書を見つける | ベクトルデータベース、埋め込みモデル |
| 拡張(Augmented) | 検索結果でコンテキストを補強 | プロンプトエンジニアリング |
| 生成(Generation) | コンテキストを基に回答生成 | LLM(GPT-4, Claude等) |
| メリット | 最新情報の活用、ハルシネーション低減 | - |
| 適用例 | 社内Q&A、ドキュメント検索、カスタマーサポート | - |
RAGの構成要素
1. 文書の前処理とチャンク分割
RAGの最初のステップは、文書を適切なサイズに分割することです。
from langchain.text_splitter import RecursiveCharacterTextSplitter
# テキストを意味のある単位で分割
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000, # チャンクのサイズ(文字数)
chunk_overlap=200, # チャンク間のオーバーラップ
length_function=len,
separators=["\n\n", "\n", "。", "、", " ", ""]
)
# 文書を分割
chunks = text_splitter.split_text(document_text)
# メタデータを付与
documents = [
{
"content": chunk,
"metadata": {
"source": "document_name.pdf",
"page": page_num,
"chunk_id": idx
}
}
for idx, chunk in enumerate(chunks)
]チャンク分割のポイント:
- サイズ選択: 500-1500文字が一般的(用途により調整)
- オーバーラップ: 文脈の連続性を保つため10-20%のオーバーラップを設定
- 区切り文字: 段落、文、句読点の順で優先的に分割
2. 埋め込みベクトルの生成
文書を数値ベクトルに変換し、意味的類似性を計算可能にします。
from openai import OpenAI
client = OpenAI(api_key="YOUR_API_KEY")
def create_embeddings(texts):
"""テキストリストを埋め込みベクトルに変換"""
response = client.embeddings.create(
model="text-embedding-3-small", # コスト効率が良い
input=texts
)
return [item.embedding for item in response.data]
# チャンクごとに埋め込みを生成
embeddings = create_embeddings([doc["content"] for doc in documents])
# 文書と埋め込みを紐付け
for doc, embedding in zip(documents, embeddings):
doc["embedding"] = embedding埋め込みモデルの選択:
- text-embedding-3-small: コスト効率重視(推奨)
- text-embedding-3-large: 精度重視
- 日本語特化モデル: 日本語文書が中心の場合
3. ベクトルデータベースへの格納
埋め込みベクトルを効率的に検索できるデータベースに格納します。
from qdrant_client import QdrantClient
from qdrant_client.models import Distance, VectorParams, PointStruct
# Qdrantクライアントの初期化
client = QdrantClient(url="http://localhost:6333")
# コレクション作成
collection_name = "documents"
client.create_collection(
collection_name=collection_name,
vectors_config=VectorParams(
size=1536, # text-embedding-3-smallの次元数
distance=Distance.COSINE
)
)
# データを格納
points = [
PointStruct(
id=idx,
vector=doc["embedding"],
payload={
"content": doc["content"],
"metadata": doc["metadata"]
}
)
for idx, doc in enumerate(documents)
]
client.upsert(
collection_name=collection_name,
points=points
)4. 検索とコンテキスト構築
ユーザーの質問から関連文書を検索し、コンテキストを構築します。
def search_documents(query, top_k=5):
"""質問に関連する文書を検索"""
# 質問を埋め込みベクトルに変換
query_embedding = create_embeddings([query])[0]
# ベクトル検索
search_result = client.search(
collection_name=collection_name,
query_vector=query_embedding,
limit=top_k,
score_threshold=0.7 # 類似度の閾値
)
# 検索結果を整形
contexts = []
for hit in search_result:
contexts.append({
"content": hit.payload["content"],
"score": hit.score,
"source": hit.payload["metadata"]["source"]
})
return contexts
# 実行例
query = "RAGの実装方法について教えてください"
relevant_docs = search_documents(query, top_k=3)5. LLMへのプロンプト構築と生成
検索結果をコンテキストとしてLLMに渡し、回答を生成します。
def generate_answer(query, contexts):
"""コンテキストを使って回答を生成"""
# コンテキストを文字列に整形
context_text = "\n\n".join([
f"[出典: {ctx['source']}]\n{ctx['content']}"
for ctx in contexts
])
# プロンプト構築
prompt = f"""以下のコンテキストを参考に、質問に答えてください。
コンテキストに含まれない情報については「情報が見つかりませんでした」と答えてください。
コンテキスト:
{context_text}
質問: {query}
回答:"""
# LLMで生成
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": "system", "content": "あなたは親切なアシスタントです。提供されたコンテキストのみを使って正確に回答してください。"},
{"role": "user", "content": prompt}
],
temperature=0.3 # 低めに設定して幻覚を抑制
)
return {
"answer": response.choices[0].message.content,
"sources": [ctx["source"] for ctx in contexts]
}
# 実行例
result = generate_answer(query, relevant_docs)
print(f"回答: {result['answer']}")
print(f"出典: {', '.join(result['sources'])}")実装パターン
パターン1: シンプルRAG
最も基本的な実装パターンです。
class SimpleRAG:
def __init__(self, vector_store, llm_client):
self.vector_store = vector_store
self.llm_client = llm_client
def query(self, question, top_k=5):
# 1. 関連文書を検索
docs = self.vector_store.search(question, top_k=top_k)
# 2. コンテキストを構築
context = "\n".join([doc["content"] for doc in docs])
# 3. LLMで回答生成
answer = self.llm_client.generate(
prompt=f"コンテキスト: {context}\n質問: {question}"
)
return answer
# 使用例
rag = SimpleRAG(vector_store=client, llm_client=openai_client)
answer = rag.query("RAGの利点は何ですか?")パターン2: ハイブリッド検索
ベクトル検索とキーワード検索を組み合わせた高度なパターンです。
from rank_bm25 import BM25Okapi
class HybridRAG:
def __init__(self, vector_store, documents):
self.vector_store = vector_store
self.documents = documents
# BM25インデックスの構築
tokenized_docs = [doc["content"].split() for doc in documents]
self.bm25 = BM25Okapi(tokenized_docs)
def hybrid_search(self, query, top_k=5, alpha=0.5):
"""
ベクトル検索とBM25を組み合わせた検索
alpha: ベクトル検索の重み(0.0-1.0)
"""
# ベクトル検索
vector_results = self.vector_store.search(query, limit=top_k*2)
vector_scores = {r.id: r.score for r in vector_results}
# BM25検索
tokenized_query = query.split()
bm25_scores = self.bm25.get_scores(tokenized_query)
# スコアを正規化して結合
combined_scores = {}
for idx, doc in enumerate(self.documents):
vector_score = vector_scores.get(idx, 0) * alpha
bm25_score = bm25_scores[idx] * (1 - alpha)
combined_scores[idx] = vector_score + bm25_score
# トップKを取得
top_indices = sorted(
combined_scores.keys(),
key=lambda x: combined_scores[x],
reverse=True
)[:top_k]
return [self.documents[idx] for idx in top_indices]パターン3: 再ランキング付きRAG
検索結果を再評価して精度を向上させるパターンです。
from sentence_transformers import CrossEncoder
class ReRankingRAG:
def __init__(self, vector_store, llm_client):
self.vector_store = vector_store
self.llm_client = llm_client
# 再ランキングモデル
self.reranker = CrossEncoder('cross-encoder/ms-marco-MiniLM-L-6-v2')
def query(self, question, initial_k=20, final_k=5):
# 1. 初期検索(多めに取得)
candidates = self.vector_store.search(question, top_k=initial_k)
# 2. 再ランキング
pairs = [[question, doc["content"]] for doc in candidates]
scores = self.reranker.predict(pairs)
# 3. スコアでソートして上位を選択
ranked_docs = sorted(
zip(candidates, scores),
key=lambda x: x[1],
reverse=True
)[:final_k]
# 4. LLMで回答生成
context = "\n".join([doc["content"] for doc, _ in ranked_docs])
answer = self.llm_client.generate(
prompt=f"コンテキスト: {context}\n質問: {question}"
)
return answerパフォーマンス最適化
1. チャンクサイズの最適化
import matplotlib.pyplot as plt
def evaluate_chunk_sizes(queries, ground_truth, sizes=[500, 1000, 1500, 2000]):
"""異なるチャンクサイズでの精度を評価"""
results = {}
for size in sizes:
# チャンクを再分割
splitter = RecursiveCharacterTextSplitter(chunk_size=size)
chunks = splitter.split_documents(documents)
# ベクトルストアを再構築
vector_store = build_vector_store(chunks)
# 精度を評価
accuracy = evaluate_accuracy(vector_store, queries, ground_truth)
results[size] = accuracy
return results
# 結果の可視化
results = evaluate_chunk_sizes(test_queries, test_answers)
plt.plot(results.keys(), results.values())
plt.xlabel('Chunk Size')
plt.ylabel('Accuracy')
plt.title('Chunk Size vs Accuracy')
plt.show()2. キャッシング戦略
from functools import lru_cache
import hashlib
class CachedRAG:
def __init__(self, vector_store, llm_client):
self.vector_store = vector_store
self.llm_client = llm_client
self.embedding_cache = {}
def get_cached_embedding(self, text):
"""埋め込みをキャッシュ"""
text_hash = hashlib.md5(text.encode()).hexdigest()
if text_hash not in self.embedding_cache:
embedding = create_embeddings([text])[0]
self.embedding_cache[text_hash] = embedding
return self.embedding_cache[text_hash]
@lru_cache(maxsize=1000)
def cached_query(self, question):
"""頻繁な質問をキャッシュ"""
return self.query(question)3. バッチ処理
def batch_index_documents(documents, batch_size=100):
"""大量の文書を効率的にインデックス化"""
for i in range(0, len(documents), batch_size):
batch = documents[i:i + batch_size]
# バッチで埋め込み生成
texts = [doc["content"] for doc in batch]
embeddings = create_embeddings(texts)
# バッチで格納
points = [
PointStruct(
id=i + idx,
vector=embedding,
payload={"content": doc["content"]}
)
for idx, (doc, embedding) in enumerate(zip(batch, embeddings))
]
client.upsert(
collection_name=collection_name,
points=points
)
print(f"Processed {min(i + batch_size, len(documents))}/{len(documents)} documents")本番運用のポイント
1. モニタリング
import time
from datetime import datetime
class MonitoredRAG:
def __init__(self, vector_store, llm_client):
self.vector_store = vector_store
self.llm_client = llm_client
self.metrics = []
def query(self, question):
start_time = time.time()
try:
# 検索
search_start = time.time()
docs = self.vector_store.search(question, top_k=5)
search_time = time.time() - search_start
# 生成
gen_start = time.time()
answer = self.llm_client.generate(question, docs)
gen_time = time.time() - gen_start
# メトリクスを記録
self.metrics.append({
"timestamp": datetime.now().isoformat(),
"question": question,
"search_time": search_time,
"generation_time": gen_time,
"total_time": time.time() - start_time,
"num_docs_retrieved": len(docs),
"status": "success"
})
return answer
except Exception as e:
self.metrics.append({
"timestamp": datetime.now().isoformat(),
"question": question,
"status": "error",
"error": str(e)
})
raise2. エラーハンドリング
class RobustRAG:
def query(self, question, max_retries=3):
for attempt in range(max_retries):
try:
# 検索
docs = self.vector_store.search(question, top_k=5)
# 検索結果が空の場合
if not docs:
return {
"answer": "関連する情報が見つかりませんでした。",
"confidence": "low"
}
# 生成
answer = self.llm_client.generate(question, docs)
return {
"answer": answer,
"confidence": "high",
"sources": [doc["source"] for doc in docs]
}
except Exception as e:
if attempt == max_retries - 1:
return {
"answer": "申し訳ございません。エラーが発生しました。",
"error": str(e)
}
time.sleep(2 ** attempt) # Exponential backoff3. コスト管理
class CostAwareRAG:
def __init__(self, vector_store, llm_client):
self.vector_store = vector_store
self.llm_client = llm_client
self.cost_tracker = {
"embedding_tokens": 0,
"llm_input_tokens": 0,
"llm_output_tokens": 0
}
def estimate_cost(self):
"""コストを見積もり"""
# OpenAI pricing (2024年時点)
embedding_cost = self.cost_tracker["embedding_tokens"] * 0.00002 / 1000
input_cost = self.cost_tracker["llm_input_tokens"] * 0.01 / 1000
output_cost = self.cost_tracker["llm_output_tokens"] * 0.03 / 1000
return {
"embedding_cost": embedding_cost,
"llm_cost": input_cost + output_cost,
"total_cost": embedding_cost + input_cost + output_cost
}よくある課題と対策
課題1: ハルシネーション(幻覚)
対策:
def verify_answer_with_context(answer, contexts):
"""回答がコンテキストに基づいているか検証"""
verification_prompt = f"""
以下の回答が、提供されたコンテキストのみに基づいているか評価してください。
コンテキスト:
{contexts}
回答:
{answer}
コンテキスト外の情報が含まれている場合は「False」、
すべてコンテキストに基づいている場合は「True」と答えてください。
"""
result = llm_client.generate(verification_prompt)
return "True" in result課題2: 検索精度の低下
対策:
- メタデータフィルタリングの活用
- ハイブリッド検索の導入
- 定期的な埋め込みモデルの更新
def search_with_filters(query, filters=None):
"""メタデータフィルタを使った検索"""
search_params = {
"query_vector": create_embeddings([query])[0],
"limit": 5
}
if filters:
search_params["filter"] = filters
# 例: 特定の日付以降の文書のみ検索
# filters = {
# "must": [
# {"key": "date", "range": {"gte": "2024-01-01"}}
# ]
# }
return client.search(collection_name, **search_params)課題3: レスポンス時間の長さ
対策:
- 並列処理の活用
- 結果のキャッシング
- 軽量なモデルの使用
import asyncio
async def parallel_rag_query(questions):
"""複数の質問を並列処理"""
tasks = [
asyncio.create_task(rag.async_query(q))
for q in questions
]
results = await asyncio.gather(*tasks)
return results実運用での成果
私たちの実装では、以下の成果を達成しました:
- 回答精度: 従来のFAQシステムと比較して 85%→93%に向上
- レスポンス時間: 平均 2.5秒以内で回答
- コスト削減: カスタマーサポートの対応工数を 40%削減
- ユーザー満足度: NPS(Net Promoter Score)が +15ポイント向上
おわりに
RAGは、LLMの能力を最大限に引き出すための実用的な技術です。本記事で紹介した実装パターンと最適化手法を組み合わせることで、高精度で実用的なシステムを構築できます。
RAG導入の際は、以下のポイントを押さえることをお勧めします:
- 適切なチャンクサイズ: 用途に応じて500-1500文字で調整
- ハイブリッド検索: ベクトル検索とキーワード検索の組み合わせ
- 再ランキング: 初期検索結果の精度向上
- モニタリング: パフォーマンスとコストの継続的な監視
- エラーハンドリング: ユーザー体験を損なわない適切な対応
弊社では、これらの知見を活かして、お客様のビジネスに最適なRAGシステムの構築を支援しています。RAGの導入や最適化についてお困りの際は、お気軽にご相談ください。