社内ナレッジが散在する組織における、高精度ドキュメント検索システムの構築ガイド(RAG実践)
はじめに
この記事の要点
Q: RAGとは何ですか?
Q: ベクトル検索のメリットは?
Q: エンタープライズ導入の重要ポイントは?
Q: 回答の質を向上させるには?
「Slackで質問したことが、過去に誰かが答えたことだった」「社内のWikiを探しても、目的の情報になかなか辿り着けない」——。企業規模が大きくなるにつれ、社内に蓄積された膨大な「ナレッジ」を必要な時に取り出すことは、大きな課題となります。
近年、この課題を解決する強力な手段として注目されているのが、LLM(大規模言語モデル)を活用したAI検索システムです。特に、LLMの知識に外部データを組み合わせる RAG(Retrieval-Augmented Generation / 検索拡張生成) という手法は、ハルシネーション(嘘の生成)を抑えつつ、社内独自の情報を正確に検索できるため、多くの企業で導入が進んでいます。
この記事では、RAGを活用した「社内ナレッジ検索システム」の仕組みやメリット、そして実務での構築において重要となる設計のポイントについて解説します。
RAGを活用した社内ナレッジ検索システムとはどのようなものですか?
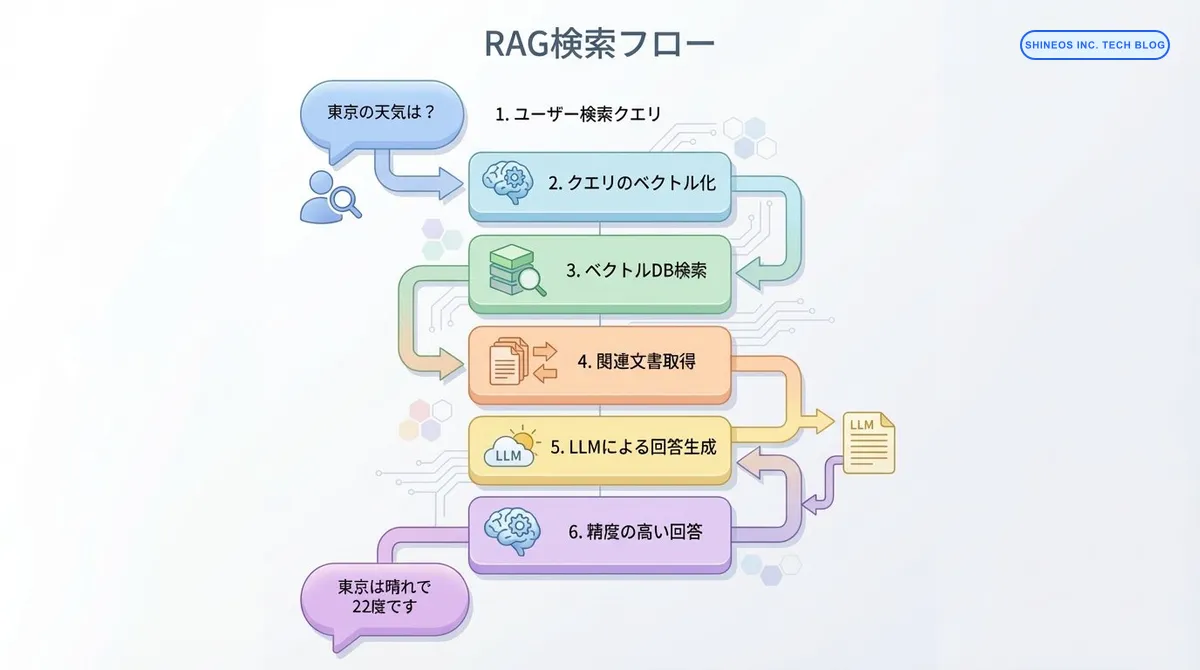
社内ナレッジ検索システムとは、社内のWiki、ドキュメント、チャットログ、メールなどの膨大な情報を横断的に検索し、必要な情報を提示するシステムです。これにLLMとRAGを組み合わせることで、「単に文書を探す」だけでなく、「質問に対して社内の情報を元に回答を生成する」ことが可能になります。
従来の全文検索(キーワードベース)では「完全一致」や「部分一致」に依存するため、表現が異なると見つけられませんでした。一方、RAGベースの検索では、ベクトル埋め込み(Embedding)によって 意味的な類似性 を捉えるため、「障害対応の手順書」と検索すれば「トラブルシューティングガイド」も候補として提示されます。
まとめ
この記事のポイントを簡潔にまとめます。
- 社内ナレッジが散在する課題は、RAG技術による統合検索システムで解決できる
- ベクトル埋め込みと意味検索により、キーワード一致に頼らない高精度な情報取得が可能
- 段階的な実装アプローチ(PoC → 本格運用)により、リソースが限られた組織でも導入できる
- 継続的なチューニング(チャンク分割、メタデータ活用、再ランキング)が検索精度向上の鍵
- コスト最適化とセキュリティ設計を最初から組み込むことで、長期運用が可能になる
RAG(検索拡張生成)にはどのようなメリットがありますか?
従来型検索の限界
従来のキーワードベース検索には、以下のような課題がありました。
| 課題 | 説明 |
|---|---|
| 表現の揺れに弱い | 「API連携」と検索しても「外部システム統合」という表現の文書は見つからない |
| 文脈を理解できない | 「障害時の対応」を探しても、タイトルに「トラブルシューティング」とある文書はヒットしない |
| 部分一致の限界 | 複数の単語を組み合わせた複雑な質問には対応できない |
| 検索結果の順位付けが不正確 | 単純な出現頻度ベースのため、本当に必要な情報が下位に埋もれる |
RAGによる解決アプローチ
RAGは以下の仕組みで、これらの課題を解決します。
- 意味的な類似性の理解: テキストをベクトル化し、意味が近い文書を数学的に計算
- コンテキストの考慮: 質問と文書の文脈を比較し、関連性の高い情報を優先
- LLMによる回答生成: 検索結果を元に、自然な文章で回答を生成
- 継続的な学習: ユーザーのフィードバックを元に検索精度を改善
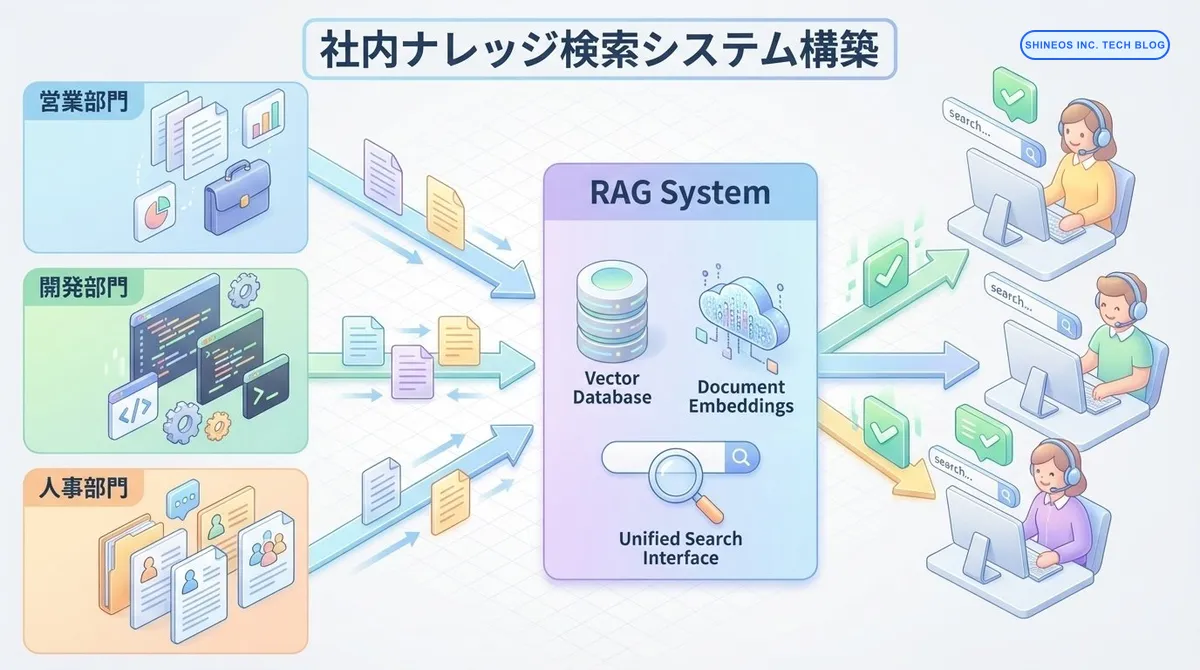
社内ナレッジ検索システムの全体アーキテクチャ
RAGベースの検索システムは、以下のコンポーネントで構成されます。
システム構成図
各コンポーネントの役割
| コンポーネント | 役割 | 技術選択例 |
|---|---|---|
| データソース統合 | Slack、Google Drive、Notionなどからドキュメントを収集 | API連携、Webhook |
| 前処理パイプライン | テキスト抽出、クリーニング、チャンク分割 | LangChain、Unstructured |
| 埋め込みモデル | テキストをベクトルに変換 | OpenAI Embeddings、sentence-transformers |
| ベクトルデータベース | 埋め込みベクトルを格納・検索 | Pinecone、Weaviate、Qdrant |
| 検索エンジン | 類似ベクトルを高速検索 | FAISS、Annoy |
| LLM | 検索結果を元に回答を生成 | GPT-4、Claude、Gemini |
| フロントエンド | ユーザーインターフェース | Slack Bot、Web UI、社内ポータル統合 |
段階的な構築ステップ
実際のプロジェクトでは、いきなり完璧なシステムを作るのではなく、段階的に機能を拡張していくアプローチが成功の鍵です。
Step 1: PoC(概念実証)- 最小構成で効果検証
まずは、限定的なデータソース(例: Notion の特定ワークスペース)だけを対象に、検索システムの効果を検証します。
実装の流れ:
from langchain.document_loaders import NotionDirectoryLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Pinecone
import pinecone
# 1. Notionからドキュメントを読み込み
loader = NotionDirectoryLoader("path/to/notion/export")
documents = loader.load()
# 2. チャンク分割(意味のある単位で分割)
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200, # 文脈の連続性を保つためのオーバーラップ
separators=["\n\n", "\n", "。", "、", " "]
)
chunks = text_splitter.split_documents(documents)
# 3. 埋め込みベクトル生成
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
# 4. ベクトルDBに保存
pinecone.init(api_key="your-api-key", environment="us-west1-gcp")
index_name = "enterprise-knowledge-base"
vectorstore = Pinecone.from_documents(
chunks,
embeddings,
index_name=index_name
)
print(f"✅ {len(chunks)}個のチャンクをベクトルDBに登録しました")検索の実装:
from langchain.chains import RetrievalQA
from langchain.chat_models import ChatOpenAI
# LLMの初期化
llm = ChatOpenAI(model="gpt-4", temperature=0)
# RAGチェーンの構築
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=vectorstore.as_retriever(search_kwargs={"k": 5}),
return_source_documents=True
)
# 質問の実行
query = "新規プロジェクトを開始する際の承認フローを教えてください"
result = qa_chain({"query": query})
print(f"回答: {result['result']}")
print(f"\n参照元: {[doc.metadata['source'] for doc in result['source_documents']]}")PoCフェーズのポイント
- データソースは1つに絞る(Notionのみ、など)
- ユーザーは限定的(開発チームのみ、など)
- 期間は2-4週間程度で効果測定
- 検索精度とユーザー満足度を数値で評価
Step 2: データソース拡張と精度向上
PoCで効果が確認できたら、データソースを拡張し、検索精度を高めます。
複数データソースの統合:
from langchain.document_loaders import (
NotionDirectoryLoader,
SlackDirectoryLoader,
GoogleDriveLoader,
ConfluenceLoader
)
# 各データソースからロード
loaders = [
NotionDirectoryLoader("path/to/notion"),
SlackDirectoryLoader("path/to/slack/export"),
GoogleDriveLoader(folder_id="your-folder-id"),
ConfluenceLoader(url="https://your-company.atlassian.net", space_key="TECH")
]
all_documents = []
for loader in loaders:
docs = loader.load()
all_documents.extend(docs)
print(f"合計 {len(all_documents)} 件のドキュメントを収集しました")メタデータの活用:
検索精度を向上させるために、メタデータを活用します。
# メタデータを付与してチャンク化
for chunk in chunks:
chunk.metadata.update({
"source_type": "notion", # データソースの種類
"department": "engineering", # 部門
"created_at": "2025-01-15", # 作成日
"author": "田中太郎", # 作成者
"tags": ["開発", "API", "設計"] # タグ
})
# メタデータフィルタを使った検索
retriever = vectorstore.as_retriever(
search_type="similarity",
search_kwargs={
"k": 10,
"filter": {
"department": "engineering",
"source_type": {"$in": ["notion", "confluence"]}
}
}
)Step 3: 検索精度のチューニング
検索精度を最大化するためのテクニックを導入します。
1. ハイブリッド検索(ベクトル検索 + キーワード検索)
from langchain.retrievers import EnsembleRetriever
from langchain.retrievers import BM25Retriever
# ベクトル検索
vector_retriever = vectorstore.as_retriever(search_kwargs={"k": 10})
# キーワード検索(BM25)
bm25_retriever = BM25Retriever.from_documents(chunks)
bm25_retriever.k = 10
# 両方を組み合わせたハイブリッド検索
ensemble_retriever = EnsembleRetriever(
retrievers=[vector_retriever, bm25_retriever],
weights=[0.7, 0.3] # ベクトル検索を重視
)2. 再ランキング(Reranking)
検索結果を再評価して、より関連性の高いものを上位に持ってきます。
from langchain.retrievers import ContextualCompressionRetriever
from langchain.retrievers.document_compressors import CohereRerank
# Cohereの再ランキングモデル
compressor = CohereRerank(model="rerank-english-v2.0")
# 再ランキングを適用
compression_retriever = ContextualCompressionRetriever(
base_compressor=compressor,
base_retriever=ensemble_retriever
)3. クエリ拡張(Query Expansion)
ユーザーの質問を拡張して、より多くの関連情報を取得します。
from langchain.prompts import PromptTemplate
query_expansion_template = PromptTemplate(
input_variables=["query"],
template="""
元の質問: {query}
この質問に関連する検索キーワードを3つ生成してください。
元の質問とは異なる表現や、関連する概念を含めてください。
検索キーワード:
1.
2.
3.
"""
)
# LLMで質問を拡張
expanded_queries = llm.predict(query_expansion_template.format(query=query))本番運用での考慮事項
セキュリティとアクセス制御
社内ナレッジには機密情報が含まれるため、適切なアクセス制御が必須です。
実装例:
def filter_documents_by_permission(user_id, documents):
"""
ユーザーの権限に基づいてドキュメントをフィルタリング
"""
user_departments = get_user_departments(user_id)
user_roles = get_user_roles(user_id)
filtered_docs = []
for doc in documents:
# 部門による制限
if doc.metadata.get("department") not in user_departments:
if "confidential" in doc.metadata.get("tags", []):
continue
# 役職による制限
required_role = doc.metadata.get("min_role_required")
if required_role and user_roles[0] < required_role:
continue
filtered_docs.append(doc)
return filtered_docsコスト最適化
RAGシステムは、埋め込みの生成とLLMの推論でコストがかかります。
最適化のポイント:
| 項目 | 最適化手法 |
|---|---|
| 埋め込み生成 | バッチ処理、増分更新のみ実行、小型モデル(text-embedding-3-small)使用 |
| ベクトルDB | 検索結果数を制限(top_k=5-10)、不要なメタデータを削除 |
| LLM推論 | キャッシュの活用、小型モデル(GPT-3.5)をまず試す、ストリーミング応答 |
キャッシュの実装例:
from functools import lru_cache
import hashlib
@lru_cache(maxsize=1000)
def cached_search(query_hash, k=5):
"""
同じ質問は結果をキャッシュ
"""
results = vectorstore.similarity_search(query, k=k)
return results
# 使用例
query = "プロジェクト承認フロー"
query_hash = hashlib.md5(query.encode()).hexdigest()
results = cached_search(query_hash)モニタリングと改善
継続的に検索品質を改善するために、メトリクスを記録します。
import logging
from datetime import datetime
def log_search_metrics(query, results, user_feedback):
"""
検索メトリクスの記録
"""
metrics = {
"timestamp": datetime.now().isoformat(),
"query": query,
"num_results": len(results),
"top_result_score": results[0].metadata.get("score") if results else 0,
"user_clicked": user_feedback.get("clicked_result"),
"user_satisfied": user_feedback.get("satisfied"), # True/False
"search_latency_ms": user_feedback.get("latency")
}
logging.info(f"Search Metrics: {metrics}")
# データベースやログ分析ツールに送信
send_to_analytics(metrics)改善のためのKPI:
- 検索成功率(ユーザーが求める情報を見つけられた割合)
- 平均検索時間
- クリックスルー率(検索結果のクリック率)
- ユーザー満足度スコア
実際の導入事例から学ぶベストプラクティス
私たちShineosでは、複数の企業でRAGベースの社内検索システムを導入支援してきました。その中で見えてきた成功のポイントをご紹介します。
失敗パターンと対策
| 失敗パターン | 原因 | 対策 |
|---|---|---|
| 検索結果が的外れ | チャンク分割が適切でない | セクション単位で分割、オーバーラップを調整 |
| 古い情報が返ってくる | 増分更新の仕組みがない | 定期的な再インデックス、タイムスタンプ重視 |
| 特定部門の情報が偏る | データソースの収集が不均衡 | 全部門からバランス良くデータ収集 |
| 回答が長すぎる | プロンプト設計が不適切 | 「簡潔に答えてください」を明示 |
成功のための5つのポイント
- 小さく始めて段階的に拡張: 最初から完璧を目指さない
- ユーザーフィードバックを最優先: 「この回答は役立った?」ボタンを必ず設置
- 定期的なデータ更新: 週次または日次で増分インデックス
- 部門横断のチームで運用: エンジニアだけでなく、各部門の代表者を巻き込む
- 明確なKPIを設定: 導入効果を数値で測定
よくある質問
既存の社内検索ツールと何が違うのですか?
従来の社内検索(例: Google Workspace の検索機能)は、キーワードの完全一致や部分一致に依存しています。一方、RAGベースの検索は 意味的な類似性 を理解するため、表現が異なる文書も見つけられます。また、LLMが回答を生成するため、複数の文書をまたいだ要約も可能です。
導入にどれくらいのコストがかかりますか?
初期構築(PoC)で月額5-10万円程度(OpenAI API、ベクトルDB利用料)が目安です。本格運用では、ドキュメント量やユーザー数に応じて月額20-50万円程度です。自社でオンプレミス運用する場合は、初期投資が大きくなりますが、ランニングコストは抑えられます。
どれくらいの期間で効果が出ますか?
PoCフェーズ(2-4週間)で効果検証が可能です。ユーザーからのフィードバックを元に、3ヶ月程度で実用レベルに到達するケースが多いです。
セキュリティ面での懸念はありますか?
機密情報を扱う場合は、以下の対策が推奨されます。
- オンプレミスまたはVPC内でのホスティング
- エンドツーエンド暗号化
- アクセスログの記録と監査
- ユーザー権限に基づくフィルタリング
OpenAIなどのクラウドサービスを使う場合、データ保持ポリシー(30日後に削除など)を確認してください。
日本語の精度は英語と比べてどうですか?
OpenAIのtext-embedding-3シリーズやGPT-4は、日本語でも高い精度を発揮します。ただし、専門用語が多い業界(医療、法律など)では、ドメイン特化型のモデルをファインチューニングすることで精度が向上します。
おわりに
社内ナレッジの散在という課題は、多くの組織が抱えている共通の悩みです。RAG技術を活用した検索システムを導入することで、情報を探す時間を大幅に削減し、組織全体の生産性を向上させることができます。
重要なのは、最初から完璧なシステムを目指すのではなく、小さく始めて段階的に改善していくアプローチです。PoCで効果を確認し、ユーザーのフィードバックを元に継続的に精度を高めていくことが成功の鍵となります。
私たちShineosでは、RAGを活用した社内ナレッジ検索システムの構築支援を行っています。データソースの統合から検索精度の最適化、本番運用まで、トータルでサポートいたします。ご興味のある方は、ぜひお気軽にご相談ください。