AIエージェントワークフローの設計パターン - 業務自動化を成功させる実践的アプローチ
はじめに
この記事の要点
Q: AIエージェントワークフローとは何ですか?
Q: どのような設計パターンがありますか?
Q: 各パターンの実装ポイントは?
Q: 堅牢なシステムを構築するには?
AIエージェントの導入を検討する企業が増えていますが、「どのように業務プロセスに組み込むべきか」という設計段階で課題に直面するケースが少なくありません。単にLLMを呼び出すだけでは不十分で、業務フローに適した設計パターンを理解し、適切に実装することが成功の鍵となります。
本記事では、AIエージェントを業務自動化に活用する際の実践的な設計パターンを、具体的な実装例とともに解説します。エンジニアやプロダクトマネージャーの方々が、自社の業務に最適なワークフロー設計を行えるよう、実務で役立つ知見を共有します。
AIエージェントワークフローとはどのようなものですか?
AIエージェントワークフローとは、AIエージェントが自律的にタスクを実行するための一連の処理フローを定義したものです。従来のRPA(Robotic Process Automation)が決められた手順を実行するのに対し、AIエージェントワークフローはLLMの推論能力を活用し、状況に応じて柔軟に判断しながら処理を進めることができます。
ワークフロー設計を最適化するメリットとは?
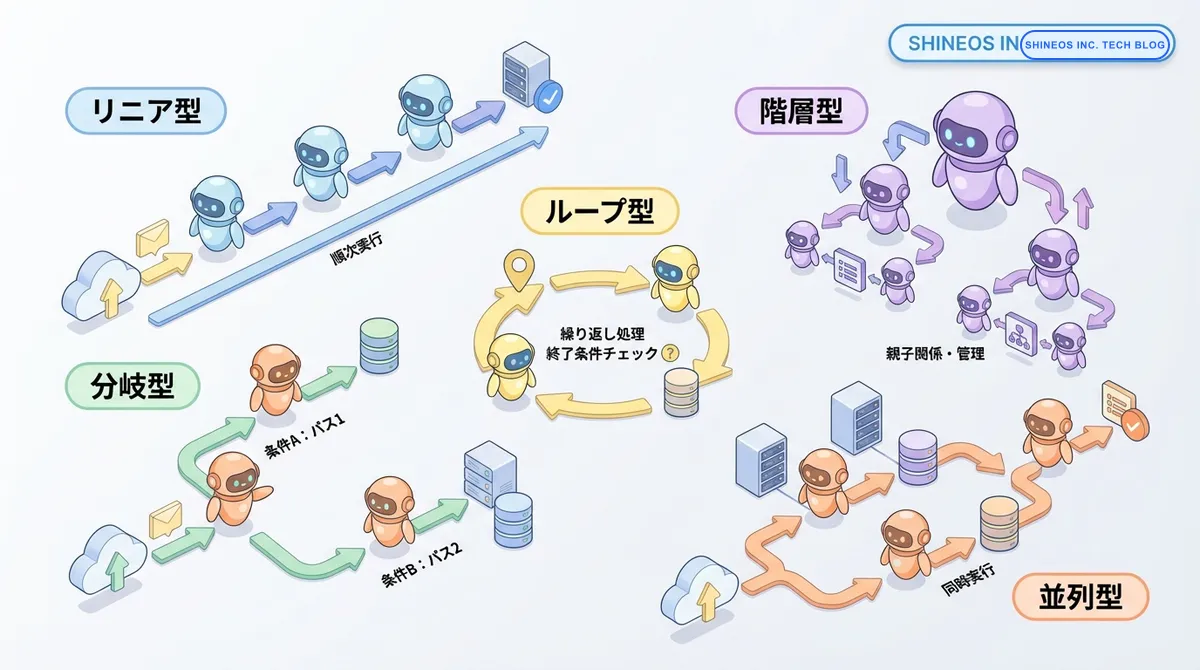
AIエージェントワークフローの設計パターンは、業務の特性や要件に応じて適切に選択する必要があります。以下に主要なパターンの特徴を整理します。
| パターン | 適用シーン | メリット | 考慮点 |
|---|---|---|---|
| リニア型 | 定型業務の自動化 | シンプルで実装が容易 | 柔軟性に制限がある |
| 分岐型 | 条件による処理分岐が必要 | 状況に応じた最適な処理 | 分岐条件の設計が重要 |
| ループ型 | 反復処理が必要な業務 | 複雑なタスクを段階的に処理 | 無限ループの防止が必要 |
| 並列型 | 複数タスクの同時実行 | 処理時間の短縮 | リソース管理とエラーハンドリング |
| 階層型 | 複雑な業務プロセス | 専門性の高い処理が可能 | コーディネーションの複雑性 |
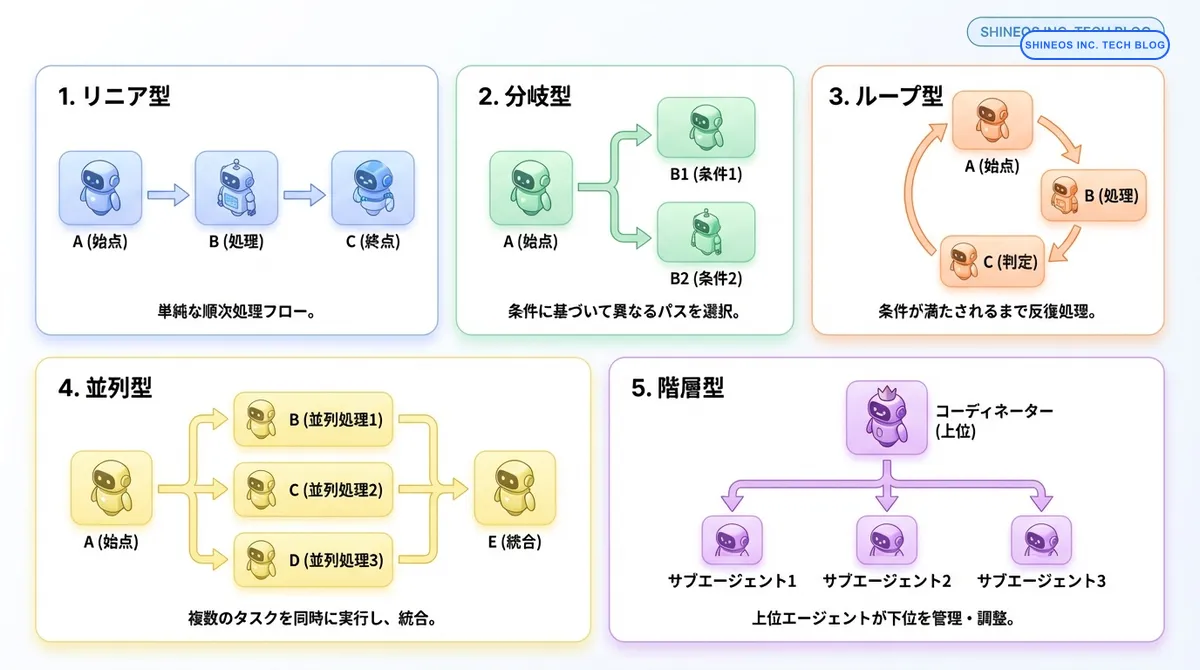
主要な設計パターン
AIエージェントワークフローの設計には、いくつかの代表的なパターンが存在します。それぞれの特徴と適用シーンを理解することで、業務要件に最適な設計を選択できます。
1. リニア型ワークフロー
最もシンプルな設計パターンで、タスクを順番に実行していく形式です。
特徴:
- 処理の流れが直線的で理解しやすい
- デバッグと保守が容易
- 定型業務の自動化に適している
適用例:
- ドキュメントの要約と翻訳
- レポート生成
- データの抽出と整形
from langchain.chains import SequentialChain
from langchain.prompts import PromptTemplate
from langchain_openai import ChatOpenAI
# LLMの初期化
llm = ChatOpenAI(model="gpt-4", temperature=0)
# ステップ1: 要約
summary_prompt = PromptTemplate(
input_variables=["text"],
template="以下のテキストを300文字程度で要約してください。\n\n{text}"
)
summary_chain = LLMChain(llm=llm, prompt=summary_prompt, output_key="summary")
# ステップ2: 重要ポイントの抽出
key_points_prompt = PromptTemplate(
input_variables=["summary"],
template="以下の要約から3つの重要ポイントを箇条書きで抽出してください。\n\n{summary}"
)
key_points_chain = LLMChain(llm=llm, prompt=key_points_prompt, output_key="key_points")
# リニア型ワークフローの構築
workflow = SequentialChain(
chains=[summary_chain, key_points_chain],
input_variables=["text"],
output_variables=["summary", "key_points"]
)
# 実行
result = workflow({"text": "長文のドキュメント..."})2. 分岐型ワークフロー
条件に基づいて処理を分岐させるパターンです。ビジネスロジックに応じた柔軟な対応が可能になります。
特徴:
- 状況に応じた最適な処理経路を選択
- 複数のシナリオに対応可能
- 意思決定ロジックの実装が必要
適用例:
- カスタマーサポートのトリアージ
- コンテンツの自動分類
- リスク評価に基づいた承認フロー
from langchain.agents import Tool, AgentExecutor, create_react_agent
from langchain_openai import ChatOpenAI
def classify_inquiry(inquiry: str) -> str:
"""問い合わせを分類"""
llm = ChatOpenAI(model="gpt-4", temperature=0)
prompt = f"""
以下の問い合わせを分類してください。
問い合わせ: {inquiry}
分類: technical / billing / general のいずれかで回答してください。
"""
return llm.predict(prompt).strip().lower()
def handle_technical(inquiry: str) -> str:
"""技術的な問い合わせ対応"""
# 技術サポート用の詳細な処理
return "技術サポートチームに転送しました。"
def handle_billing(inquiry: str) -> str:
"""請求に関する問い合わせ対応"""
# 請求処理用の処理
return "請求部門に転送しました。"
def handle_general(inquiry: str) -> str:
"""一般的な問い合わせ対応"""
# 一般対応
return "自動応答を送信しました。"
# 分岐型ワークフロー
def branching_workflow(inquiry: str) -> str:
category = classify_inquiry(inquiry)
if category == "technical":
return handle_technical(inquiry)
elif category == "billing":
return handle_billing(inquiry)
else:
return handle_general(inquiry)
# 実行
result = branching_workflow("アプリがクラッシュして起動できません")3. ループ型ワークフロー
反復処理を行うパターンで、段階的な改善や複雑なタスクの分割実行に適しています。
特徴:
- 結果を評価しながら反復的に改善
- 複雑なタスクを小さなステップに分解
- 収束条件の設定が重要
適用例:
- コード生成とレビューの反復
- コンテンツの推敲
- データ品質の段階的改善
from langchain_openai import ChatOpenAI
from langchain.prompts import PromptTemplate
def iterative_improvement_workflow(initial_text: str, max_iterations: int = 3) -> str:
llm = ChatOpenAI(model="gpt-4", temperature=0.7)
improve_prompt = PromptTemplate(
input_variables=["text", "feedback"],
template="""
以下のテキストを改善してください。
テキスト: {text}
フィードバック: {feedback}
改善版:
"""
)
evaluate_prompt = PromptTemplate(
input_variables=["text"],
template="""
以下のテキストを評価してください(1-10点)。
8点以上なら "合格"、それ以下なら改善点を指摘してください。
テキスト: {text}
評価:
"""
)
current_text = initial_text
for i in range(max_iterations):
# 評価
evaluation = llm.predict(evaluate_prompt.format(text=current_text))
if "合格" in evaluation:
print(f"イテレーション {i+1}: 品質基準を満たしました")
break
# 改善
current_text = llm.predict(
improve_prompt.format(text=current_text, feedback=evaluation)
)
print(f"イテレーション {i+1}: テキストを改善しました")
return current_text
# 実行
result = iterative_improvement_workflow("これはサンプルテキストです。")注意:
ループ型ワークフローでは、無限ループを防ぐために最大イテレーション数や収束条件を必ず設定してください。
4. 並列型ワークフロー
複数のタスクを同時に実行するパターンで、処理時間の短縮に効果的です。
特徴:
- 複数のタスクを並行して実行
- 全体の処理時間を短縮
- リソース管理とエラーハンドリングが重要
適用例:
- 複数データソースからの情報収集
- マルチモーダル処理(テキスト・画像・音声の同時処理)
- A/Bテストの同時実行
import asyncio
from langchain_openai import ChatOpenAI
from typing import List, Dict
async def analyze_sentiment(text: str, llm: ChatOpenAI) -> str:
"""感情分析"""
prompt = f"以下のテキストの感情を分析してください: {text}"
return await llm.apredict(prompt)
async def extract_keywords(text: str, llm: ChatOpenAI) -> str:
"""キーワード抽出"""
prompt = f"以下のテキストから5つのキーワードを抽出してください: {text}"
return await llm.apredict(prompt)
async def summarize(text: str, llm: ChatOpenAI) -> str:
"""要約"""
prompt = f"以下のテキストを100文字で要約してください: {text}"
return await llm.apredict(prompt)
async def parallel_workflow(text: str) -> Dict[str, str]:
llm = ChatOpenAI(model="gpt-4", temperature=0)
# 並列実行
results = await asyncio.gather(
analyze_sentiment(text, llm),
extract_keywords(text, llm),
summarize(text, llm)
)
return {
"sentiment": results[0],
"keywords": results[1],
"summary": results[2]
}
# 実行
text = "サンプルテキスト..."
result = asyncio.run(parallel_workflow(text))5. 階層型ワークフロー(マルチエージェント)
複数の専門エージェントを階層的に配置し、コーディネーターが全体を管理するパターンです。
特徴:
- 各エージェントが専門領域を担当
- スケーラブルで拡張性が高い
- コーディネーションの複雑性が増す
適用例:
- 複雑なリサーチタスク
- マルチステップの意思決定
- 専門知識が必要な業務プロセス
from langchain.agents import Tool, AgentExecutor, create_react_agent
from langchain_openai import ChatOpenAI
from langchain.prompts import PromptTemplate
# 専門エージェントの定義
class ResearchAgent:
def __init__(self):
self.llm = ChatOpenAI(model="gpt-4", temperature=0)
def research(self, topic: str) -> str:
prompt = f"以下のトピックについて調査してください: {topic}"
return self.llm.predict(prompt)
class AnalysisAgent:
def __init__(self):
self.llm = ChatOpenAI(model="gpt-4", temperature=0)
def analyze(self, data: str) -> str:
prompt = f"以下のデータを分析してください: {data}"
return self.llm.predict(prompt)
class ReportAgent:
def __init__(self):
self.llm = ChatOpenAI(model="gpt-4", temperature=0.7)
def create_report(self, analysis: str) -> str:
prompt = f"以下の分析結果からレポートを作成してください: {analysis}"
return self.llm.predict(prompt)
# コーディネーター
class CoordinatorAgent:
def __init__(self):
self.research_agent = ResearchAgent()
self.analysis_agent = AnalysisAgent()
self.report_agent = ReportAgent()
def execute(self, task: str) -> str:
# ステップ1: リサーチ
research_result = self.research_agent.research(task)
# ステップ2: 分析
analysis_result = self.analysis_agent.analyze(research_result)
# ステップ3: レポート作成
final_report = self.report_agent.create_report(analysis_result)
return final_report
# 実行
coordinator = CoordinatorAgent()
result = coordinator.execute("AI市場のトレンドをレポートしてください")実装時のベストプラクティス
AIエージェントワークフローを実装する際には、以下のポイントに注意することで、より堅牢で保守性の高いシステムを構築できます。
エラーハンドリング
AIエージェントは予期しない出力を返す可能性があるため、適切なエラーハンドリングが不可欠です。
from langchain.callbacks import get_openai_callback
import logging
def safe_agent_execution(agent_func, max_retries: int = 3):
"""リトライ機能付きのエージェント実行"""
for attempt in range(max_retries):
try:
with get_openai_callback() as cb:
result = agent_func()
logging.info(f"トークン使用量: {cb.total_tokens}")
return result
except Exception as e:
logging.error(f"試行 {attempt + 1} 失敗: {str(e)}")
if attempt == max_retries - 1:
raise
time.sleep(2 ** attempt) # 指数バックオフモニタリングとロギング
本番環境では、ワークフローの実行状況を追跡できるようにします。
import time
from contextlib import contextmanager
@contextmanager
def workflow_monitor(workflow_name: str):
"""ワークフロー実行のモニタリング"""
start_time = time.time()
logging.info(f"ワークフロー '{workflow_name}' 開始")
try:
yield
except Exception as e:
logging.error(f"ワークフロー '{workflow_name}' エラー: {str(e)}")
raise
finally:
elapsed_time = time.time() - start_time
logging.info(f"ワークフロー '{workflow_name}' 完了 (実行時間: {elapsed_time:.2f}秒)")
# 使用例
with workflow_monitor("顧客問い合わせ処理"):
result = branching_workflow(inquiry)コスト管理
LLM APIの呼び出しコストを管理するための仕組みを実装します。
class CostAwareAgent:
def __init__(self, budget_limit: float):
self.total_cost = 0.0
self.budget_limit = budget_limit
def execute_with_budget(self, agent_func):
"""予算制限付きでエージェントを実行"""
if self.total_cost >= self.budget_limit:
raise ValueError("予算上限に達しました")
with get_openai_callback() as cb:
result = agent_func()
self.total_cost += cb.total_cost
logging.info(f"累計コスト: ${self.total_cost:.4f} / ${self.budget_limit}")
return resultよくある質問
AIエージェントワークフローの実装にはどの程度のコストがかかりますか?
コストは使用するLLMモデルと処理量によって大きく変動します。GPT-4の場合、1,000トークンあたり約$0.03-0.06程度です。本番運用前にプロトタイプで実測し、予算計画を立てることをお勧めします。プロンプトの最適化やキャッシング戦略により、コストを30-50%削減できるケースもあります。
既存の業務システムとの統合はどのように行うべきですか?
API連携またはデータベース連携が一般的です。LangChainのToolやFunction Callingを活用することで、既存システムのAPIをエージェントから呼び出せます。段階的な統合アプローチとして、まずは限定的な業務から始め、徐々に拡大していく方法が推奨されます。
ワークフローのパフォーマンスを改善するには?
以下の方法が効果的です:1) 並列処理の活用、2) プロンプトの最適化によるトークン数削減、3) キャッシング戦略の導入、4) より高速なモデル(GPT-3.5-turbo等)の使用、5) バッチ処理の活用。特に並列処理は処理時間を50%以上短縮できる場合があります。
おわりに
AIエージェントワークフローの設計パターンを理解し、適切に実装することで、業務自動化の効果を最大化できます。本記事で紹介したパターンを参考に、自社の業務要件に最適な設計を検討してみてください。
重要なのは、最初から完璧なシステムを目指すのではなく、小さく始めて段階的に改善していくアプローチです。まずはリニア型や分岐型などのシンプルなパターンから始め、必要に応じてより複雑なパターンに移行していくことをお勧めします。
私たちShineosでは、AIエージェントを活用した業務自動化の支援を行っています。ご興味のある方は、ぜひお気軽にご相談ください。