プロンプトエンジニアリングのベストプラクティス - LLMの性能を最大化する技法
はじめに
この記事の要点
Q: プロンプトエンジニアリングとは何ですか?
Q: 3つの基本原則は?
Q: 複雑な推論タスクに対応する技法は?
Q: 実務運用の成功を左右する要素は?
LLM(Large Language Model)を活用したアプリケーション開発において、プロンプトの品質が出力結果に大きな影響を与えます。適切なプロンプト設計により、同じモデルでも劇的に性能を向上させることができますが、効果的なプロンプトの作成には体系的なアプローチが必要です。
本記事では、プロンプトエンジニアリングの基本原則から高度なテクニックまで、実務で即活用できる実践的な手法を具体例とともに解説します。エンジニアやプロダクト開発者の方々が、LLMの能力を最大限に引き出せるようサポートします。
プロンプトエンジニアリングとはどのような技術ですか?
プロンプトエンジニアリングとは、LLMから望ましい出力を得るために、入力テキスト(プロンプト)を最適化する技術です。モデルの再学習や微調整を必要とせず、プロンプトの工夫だけで性能を大幅に改善できるため、コスト効率が高く、迅速な開発が可能になります。
プロンプトエンジニアリングを導入するメリットとは?
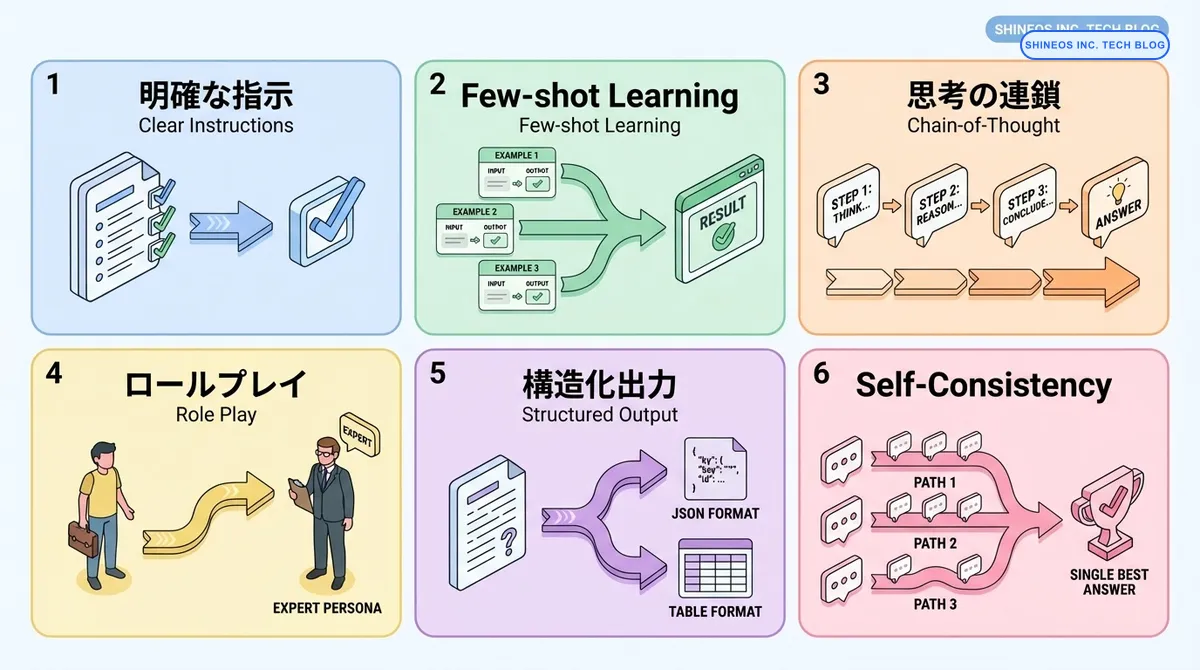
プロンプトエンジニアリングの主要テクニックと適用シーンを以下にまとめます。
| テクニック | 特徴 | 適用シーン | 効果 |
|---|---|---|---|
| 明確な指示 | 具体的で詳細な指示を提供 | あらゆるタスク | 精度向上、誤解の防止 |
| Few-shot Learning | 例示を通じた学習 | フォーマット指定、スタイル統一 | 一貫性のある出力 |
| Chain-of-Thought | 段階的な推論を促す | 複雑な問題解決、数学的計算 | 論理的精度の向上 |
| ロールプレイ | 特定の役割を割り当て | 専門的なアドバイス、対話 | 文脈に適した応答 |
| 構造化出力 | JSON/XML等の形式指定 | システム連携、データ処理 | パース可能な出力 |
| Self-Consistency | 複数回実行して最適解を選択 | 重要な意思決定、複雑な推論 | 信頼性の向上 |
基本原則:効果的なプロンプトの構成要素
プロンプトエンジニアリングには、押さえるべき基本原則があります。これらを理解することで、安定した高品質の出力を得られるようになります。
1. 明確で具体的な指示
曖昧な指示ではなく、具体的で詳細な指示を与えることが重要です。
悪い例:
テキストを要約してください。良い例:
以下のテキストを3つのポイントに要約してください。
各ポイントは50文字以内で、箇条書き形式で出力してください。
ビジネスパーソン向けに専門用語を避けて表現してください。
テキスト: [対象テキスト]2. コンテキストの提供
タスクを実行するために必要な背景情報やコンテキストを提供します。
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-4", temperature=0)
prompt = """
あなたは経験豊富なソフトウェアアーキテクトです。
以下のシステム要件に基づいて、最適なアーキテクチャ設計を提案してください。
【要件】
- ユーザー数: 月間100万人
- データ量: 日次で10GB増加
- 可用性: 99.9%以上
- レイテンシ: 200ms以内
【考慮事項】
- コスト効率
- 拡張性
- 保守性
提案:
"""
response = llm.predict(prompt)3. 出力フォーマットの指定
期待する出力の形式を明確に指定することで、後続処理がしやすくなります。
prompt = """
以下の製品レビューを分析し、JSON形式で出力してください。
レビュー: 「この製品は使いやすく、デザインも素晴らしいですが、価格が少し高いと感じました。」
出力形式:
{
"sentiment": "positive/neutral/negative",
"score": 1-10,
"positive_points": ["ポイント1", "ポイント2"],
"negative_points": ["ポイント1"],
"summary": "一文でまとめた評価"
}
"""高度なテクニック
基本原則を押さえた上で、さらに高度なテクニックを活用することで、LLMの性能を最大限に引き出せます。
1. Few-shot Learning(少数事例学習)
タスクの例を複数提示することで、モデルがパターンを学習し、一貫した出力を生成できます。
prompt = """
以下の例に従って、企業名から業種を分類してください。
例1:
企業名: トヨタ自動車
業種: 製造業(自動車)
例2:
企業名: 楽天グループ
業種: 情報通信業(Eコマース)
例3:
企業名: 三井住友銀行
業種: 金融業(銀行)
分類してください:
企業名: ソニーグループ
業種:
"""ポイント:
Few-shot Learningでは、例の質と多様性が重要です。典型的なパターンを3-5個提示することで、多くの場合で効果的な結果が得られます。
2. Chain-of-Thought(思考の連鎖)
複雑な問題を段階的に解決させることで、推論の精度を向上させます。
prompt = """
以下の問題を段階的に解いてください。各ステップの思考過程を示してください。
問題: ある商品の原価は1,000円です。この商品に30%の利益を上乗せして販売価格を設定します。
さらに、キャンペーンで販売価格から20%の割引を適用します。最終的な販売価格はいくらですか?
ステップバイステップで計算してください:
"""
# モデルの応答例:
# ステップ1: 利益を上乗せした価格を計算
# 1,000円 × (1 + 0.30) = 1,300円
#
# ステップ2: 割引を適用
# 1,300円 × (1 - 0.20) = 1,040円
#
# 答え: 最終的な販売価格は1,040円です。3. Self-Consistency(自己一貫性)
同じ問題に対して複数回推論させ、最も一貫性のある回答を選択します。
import asyncio
from collections import Counter
async def self_consistency_prompt(question: str, n_samples: int = 5):
llm = ChatOpenAI(model="gpt-4", temperature=0.7)
prompt_template = """
以下の質問に答えてください。段階的に考えて、最終的な答えを「答え: 」で始めてください。
質問: {question}
"""
# 複数回実行
tasks = [
llm.apredict(prompt_template.format(question=question))
for _ in range(n_samples)
]
responses = await asyncio.gather(*tasks)
# 答えを抽出
answers = []
for response in responses:
if "答え:" in response:
answer = response.split("答え:")[1].strip().split("\n")[0]
answers.append(answer)
# 最頻値を取得
most_common = Counter(answers).most_common(1)[0]
return most_common[0], most_common[1] / len(answers)
# 実行例
question = "5人で100個のリンゴを均等に分けると、1人あたり何個になりますか?"
answer, confidence = asyncio.run(self_consistency_prompt(question))
print(f"答え: {answer} (信頼度: {confidence:.0%})")4. ロールプレイ(役割の設定)
LLMに特定の役割やペルソナを与えることで、より適切な文脈での応答を引き出します。
# 技術専門家としての役割
tech_expert_prompt = """
あなたは20年の経験を持つクラウドアーキテクトです。
AWSを中心とした実務経験が豊富で、特にコスト最適化と高可用性設計を得意としています。
質問に対して、実践的で具体的なアドバイスを提供してください。
専門用語は必要に応じて使用し、理由と根拠を明確に説明してください。
質問: EKSクラスターのコストを削減する方法を教えてください。
"""
# ビジネスコンサルタントとしての役割
business_consultant_prompt = """
あなたは経営戦略コンサルタントです。
技術的な詳細よりも、ビジネスインパクトとROIを重視した分析を行います。
経営者にも理解しやすい言葉で、投資対効果の観点からアドバイスしてください。
質問: AI導入による業務効率化を検討していますが、優先順位をどう決めるべきですか?
"""5. 構造化プロンプト
複雑なタスクを明確なセクションに分割し、構造化されたプロンプトを作成します。
structured_prompt = """
# タスク
顧客からの問い合わせメールを分析し、適切な対応方針を提案してください。
# 入力情報
メール本文:
「先週注文した商品がまだ届きません。注文番号はORD-12345です。配送状況を教えてください。」
顧客情報:
- 会員ランク: ゴールド
- 過去の注文回数: 15回
- 過去のクレーム: 0回
# 分析項目
1. 問い合わせカテゴリ(配送/返品/不良品/その他)
2. 緊急度(高/中/低)
3. 顧客の感情(怒り/不安/中立/満足)
# 対応方針
1. 初動対応(24時間以内)
2. フォローアップ計画
3. 顧客満足度向上のための追加施策
# 出力形式
JSON形式で以下のキーを含めてください:
- category
- urgency
- sentiment
- initial_response
- follow_up_plan
- additional_actions
"""実装時のベストプラクティス
プロンプトエンジニアリングを実務で活用する際の重要なポイントをまとめます。
プロンプトのバージョン管理
# プロンプトテンプレートの管理
class PromptTemplateManager:
def __init__(self):
self.templates = {
"summarize_v1": """
以下のテキストを要約してください。
テキスト: {text}
""",
"summarize_v2": """
以下のテキストを{length}文字以内で要約してください。
重要なポイントを{num_points}つに絞って箇条書きで示してください。
テキスト: {text}
""",
}
def get_template(self, name: str, version: str = "latest"):
if version == "latest":
# 最新バージョンを取得
versions = [k for k in self.templates.keys() if k.startswith(name)]
if versions:
return self.templates[max(versions)]
return self.templates.get(f"{name}_{version}")
def format(self, name: str, **kwargs):
template = self.get_template(name)
return template.format(**kwargs)
# 使用例
manager = PromptTemplateManager()
prompt = manager.format("summarize", text="長文...", length=300, num_points=3)A/Bテストによる最適化
import random
from typing import List, Dict
class PromptABTester:
def __init__(self):
self.results = []
def test_variants(self, variants: List[str], test_input: str,
evaluation_func, n_trials: int = 10):
"""複数のプロンプトバリアントをテスト"""
for variant_name, prompt_template in variants:
scores = []
for _ in range(n_trials):
prompt = prompt_template.format(input=test_input)
output = llm.predict(prompt)
score = evaluation_func(output)
scores.append(score)
avg_score = sum(scores) / len(scores)
self.results.append({
"variant": variant_name,
"avg_score": avg_score,
"scores": scores
})
# 最良のバリアントを返す
best = max(self.results, key=lambda x: x["avg_score"])
return best
# 使用例
def evaluate_summary(output: str) -> float:
"""要約の品質を評価(0-10点)"""
# 簡易的な評価ロジック
length_score = min(10, len(output) / 30)
return length_score
variants = [
("simple", "以下を要約: {input}"),
("detailed", "以下のテキストを3つのポイントに要約してください: {input}"),
]
tester = PromptABTester()
best_variant = tester.test_variants(variants, "テストテキスト", evaluate_summary)コスト最適化
from langchain.callbacks import get_openai_callback
def cost_aware_prompting(prompt: str, max_tokens: int = 500):
"""トークン数を意識したプロンプト実行"""
llm = ChatOpenAI(model="gpt-4", max_tokens=max_tokens, temperature=0)
with get_openai_callback() as cb:
response = llm.predict(prompt)
print(f"使用トークン: {cb.total_tokens}")
print(f"コスト: ${cb.total_cost:.4f}")
if cb.total_cost > 0.1: # 閾値
print("⚠️ 警告: コストが閾値を超えました")
return response
# プロンプト圧縮の例
def compress_prompt(long_prompt: str) -> str:
"""冗長な表現を削除してトークン数を削減"""
# 不要な空白や改行を削除
compressed = " ".join(long_prompt.split())
# 冗長な表現を置換
replacements = {
"それでは、": "",
"ご確認ください。": "",
"以下の通りです。": "",
}
for old, new in replacements.items():
compressed = compressed.replace(old, new)
return compressedよくある質問
プロンプトエンジニアリングの効果を定量的に測定するには?
効果測定には以下の指標が有効です:1) タスク達成率(期待する出力が得られた割合)、2) 平均トークン数(コスト効率)、3) レスポンス時間、4) ユーザー満足度スコア。A/Bテストを実施し、統計的に有意な差があるか検証することをお勧めします。
GPT-3.5とGPT-4でプロンプト設計は変えるべきですか?
基本的なアプローチは同じですが、GPT-4はより複雑な指示を理解できるため、詳細な条件指定や多段階の推論が可能です。GPT-3.5では、シンプルで明確な指示を心がけ、必要に応じてタスクを分割することが効果的です。コストと性能のトレードオフを考慮して選択してください。
プロンプトインジェクション攻撃への対策は?
ユーザー入力を信頼せず、以下の対策を実施してください:1) 入力のサニタイゼーション(特殊文字のエスケープ)、2) システムプロンプトとユーザー入力の明確な分離、3) 出力の検証とフィルタリング、4) レート制限の実装。特に本番環境では、セキュリティレビューを徹底することが重要です。
おわりに
プロンプトエンジニアリングは、LLMの性能を最大化するための重要なスキルです。本記事で紹介した基本原則と高度なテクニックを組み合わせることで、より高品質で信頼性の高いAIアプリケーションを構築できます。
重要なのは、プロンプトを一度書いて終わりではなく、継続的に改善していくプロセスです。A/Bテストや定量的な評価を通じて、自社のユースケースに最適化されたプロンプトを作り上げていくことをお勧めします。
私たちShineosでは、LLMを活用したプロダクト開発とプロンプト最適化の支援を行っています。プロンプトエンジニアリングでお困りの際は、お気軽にご相談ください。